While Generative AI is not a new technology, the launch of Generative AI solutions like ChatGPT, Bard, and Midjourney has spiked interest in leveraging Generative AI applications for enterprise and industry-specific use cases. However, the AI models leveraged by these Generative AI applications are trained for general-purpose utility and lack business- and industry-specific knowledge. Companies trying to capitalize on the current trends and transform their business through their emerging AI capabilities are required to take a hybrid approach with their AI strategy to partly leverage existing solutions for general-purpose activities and create their own custom AI solutions specific to their business needs.
For companies to create custom Generative AI solutions, they will need to prepare their own language models, trained with proprietary business data. The custom Large Language Models (LLMs) will help companies unleash Generative AI capabilities for their business and provide them a competitive edge.
What Is a Large Language Model?
A Large Language Model (LLM) is like a smart computer program that understands and creates human-like language. It learns by reading a massive amount of text from the internet, books, and other sources. The more it reads, the better it becomes at understanding and generating written content. LLMs have many internal settings (parameters) that help them figure out the language structure.
For example, OpenAI’s GPT (Generative Pre-trained Transformer) models are a type of LLM. They’ve read billions of sentences, making them good at tasks like talking with people, creating content, and even translating languages. These versatile models can be used in different ways to make computers better at understanding and generating human language.
LLM relies on deep learning techniques and neural networks trained with billions of parameters. These parameters allow the model to capture complex patterns and structures in language. GPT-3 model released by OpenAI in June 2020 has 175 billion parameters that generate text and code with short written prompts up to 1500 words. Compared with that, the GPT-4 model launched in March 2023 has 1.76 trillion parameters and supports prompts up to 25,000 characters.
Numerous Language Models (LLMs) are accessible, including well-known ones like GPT, Gemini, Claude, LaMDA, and PaLM. In addition to these models, various open-source LLMs, including Meta’s LLaMa and MosaicML’s MPT-7B, contribute to the expansive array of language models, each trained on distinct datasets.
“Choosing the optimal language model involves assessing tradeoffs in factors such as out-of-the-box task performance, inference speed, cost, fine-tuning ability, and data security.”
LLMs offer benefits such as natural language generation, text completion, and expansion. They excel in conversational agents, chatbots, and question-answering systems, enhancing user interactions. LLMs contribute to content summarization, code generation, and translation services, improving efficiency and accessibility. Their creative capabilities make them valuable for artistic content generation. LLMs play a key role in personalization, tailoring user experiences based on individual preferences.
Organizations can choose to use an existing LLM, customize a pre-trained LLM, or build a custom LLM from scratch. Using an existing LLM provides a quick and cost-effective solution but may not have a business or industry-specific output. Customizing a pre-trained LLM enables organizations to tune the model for specific tasks and embed proprietary knowledge. Building an LLM from scratch offers the most flexibility but requires significant expertise, resources, and investment.
Importance of LLM in Generative AI Applications
Large Language Models play a pivotal role in Generative AI applications. LLMs have the potential to broaden the reach of Generative AI applications across enterprises and industries. LLMs such as GPT, Claude, LaMDA, PaLM, and Stable Diffusion are the foundational models behind Generative AI applications such as ChatGPT, Dall-E, Bard, and Midjourney. LLMs enable a new phase of research, creativity, and productivity for companies through custom Gen AI solutions.
LLMs are specifically tailored for language-related tasks, showcasing their unique role in the generative AI landscape. LLMs, coupled with other generative AI models, can generate original, creative content such as images, video, music, and text. For example, a generative AI model trained on a diverse array of movies can be elevated by integrating an LLM with a deep understanding of storytelling structures, film genres, and cinematic language. This specialized LLM can contribute to the generation of detailed scene descriptions, dialogues, and plot analyses, enriching the quality and coherence of the movies.
Utilizing both generative AI and LLMs allows for expert personalization of content for individual shoppers. LLMs decipher shopper preferences, generating personalized recommendations, while generative AI crafts tailored content, including targeted product suggestions, personalized material, and advertisements for items aligning with individual interests.
By integrating large language models with generative AI models designed for various modalities like images or audio, it becomes possible to produce multimodal content. This enables the AI system to generate text descriptions for images or develop soundtracks for videos, enhancing content creation capabilities. The synergy between language understanding and content generation in AI systems results in the creation of more engaging and immersive content that captures attention.
“Overall, their versatility in understanding, generating, and manipulating natural language text makes LLMs crucial for Generative AI applications across domains and industries.”
How Do Large Language Models work?
Large Language Models (LLMs) are like smart assistants for computers that learn by reading a massive amount of text from various sources. They understand how language works—how words and sentences fit together. Users interact with an LLM by giving it prompts, which are specific instructions or questions. When you interact with LLMs by providing a prompt, they use what they’ve learned to generate content. LLMs become better at understanding and responding through unsupervised and reinforced learning. The more you use LLMs, the better their output can be.
Creating a good prompt is important because it affects the quality of the model’s response. It involves choosing the right words and format to guide the model in generating high-quality and relevant texts. For instance, if you want the LLM to write a detective story, your prompt could be: “Create a short story about a detective solving a mystery in a small town.” The LLM will use this prompt to generate the story or provide related information. With the increased use of LLMs for enterprise use cases, prompt engineering is emerging as a new role at most companies.
What Are the Business Use Cases of Custom LLMs?
Most use cases of LLMs and Generative AI applications remain general purpose, such as chatbots, copywriting, image, and video creations. But, companies can benefit from creating custom LLMs that can address specific challenges and improve processes. For example, Bloomberg created BloombergGPT, a custom LLM solution for financial data with 50 billion parameters using GPT as the foundational model. In fact, the major growth area for Generative AI is in addressing business-specific use cases with custom LLMs.
- In the pharmaceutical industry, LLMs can analyze vast amounts of scientific literature, research papers, and clinical trial data to aid researchers in drug discovery. They assist in extracting relevant information, identifying potential targets, and summarizing findings.
- In healthcare, LLMs aid in automating the generation of clinical notes and documentation, reducing the burden on healthcare professionals. They can enhance the accuracy and efficiency of patient records, allowing for more effective patient care.
- LLMs can help greatly in supply chain optimization for manufacturing and logistics companies. LLMs can be employed to analyze and interpret unstructured data related to supply chain management. This includes historical business data, recent trends, market reports, and geopolitics data, helping businesses make informed decisions and optimize their supply chain.
- LLMs can contribute to improving fraud detection and perform early risk assessment in financial services by analyzing key factors in financial and research data. They enhance decision-making in risk management.
- In the construction industry, LLMs can assist in generating accurate and comprehensive project documentation, forecast trends, and prevent issues on construction projects. This can improve ROI on construction projects and shorten delivery timelines.
- Packaging companies can improve packaging design and come up with innovative packaging solutions using LLMs. LLMs can contribute to the creative process by generating ideas for packaging design based on input criteria and consumer preferences. They can also assist in analyzing market trends and consumer feedback to suggest innovative packaging solutions.
These use cases demonstrate a huge potential for leveraging custom LLMs in various industries, showcasing their potential to enhance efficiency, decision-making, and communication.
Limitations of Large Language Models Explained
Large Language Models (LLMs) come with inherent limitations. Firstly, they lack access to up-to-date data and cannot independently connect with the outside world, making their information static and potentially outdated. Secondly, LLMs do not possess specific knowledge about your particular data or context. Additionally, they are not well-suited for advanced reasoning tasks, particularly in complex mathematical domains. LLMs are more geared towards general reasoning rather than possessing specialized knowledge. To perform effectively, LLMs rely on users to supply them with relevant and current information.
LLMs can generate false information (“hallucinate”) when they don’t know the answer to a question. Instead of saying they don’t know, they might generate a response that sounds confident but is incorrect. Hallucination problems can spread false facts, so should be taken into account when using LLMs for tasks that require accurate information.
LLMs can show bias in their answers, often creating content that relies on stereotypes or prejudices. This happens because they learn from big datasets that might have biased info. Even with safety measures, LLMs can still produce content that’s sexist, racist, or homophobic. This is an important concern when using LLMs in things like consumer apps or research, as it can spread harmful stereotypes and biased information.
Similar to how our brain possesses vast potential for learning and understanding, the LLM exhibits remarkable general intelligence. However, like the brain, the LLM requires specific knowledge and training to excel in particular tasks. To perform the task at a good level it requires specific information and skills.
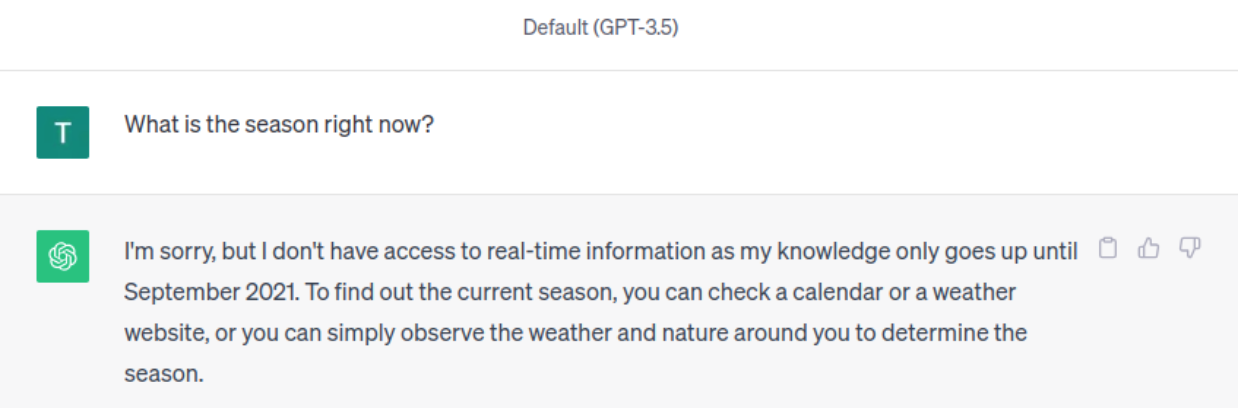
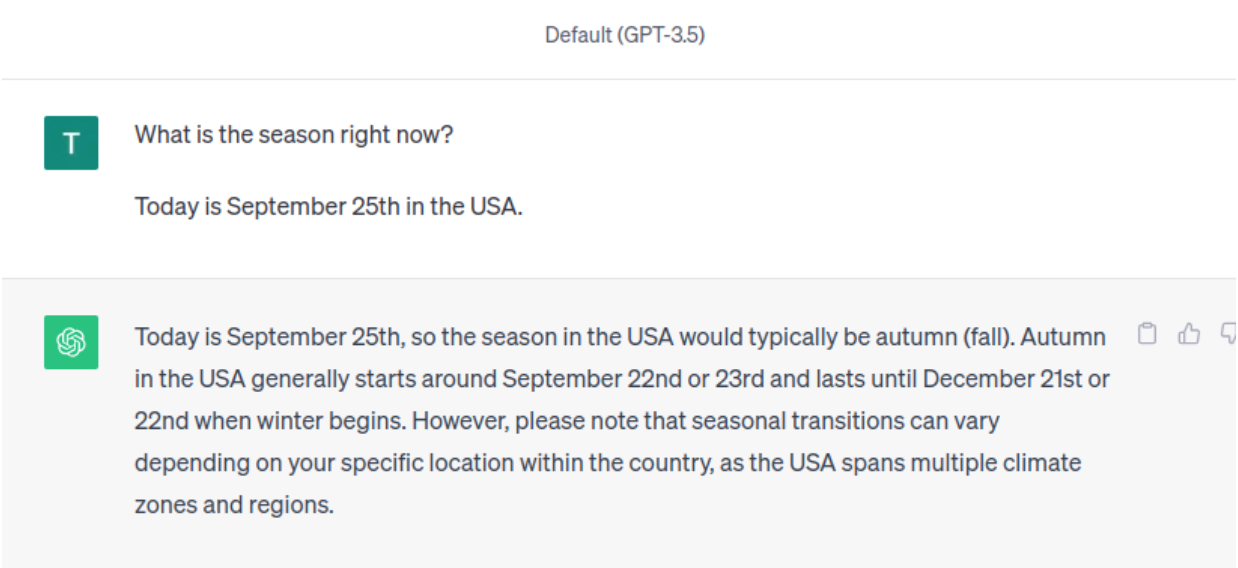
The simplest way to supply LLM with specific information is to provide a context. For example, compare GPT-3.5 responses. Here, by adding day and location, GPT-3.5 concluded that right now, it is autumn.
Without Context
With Context
Problem of hallucination and AI biases can be addressed to some degree by supplementing LLMs information stack with recent and accurate information. Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM responses by grounding the model on external data sources of knowledge to supplement the LLM’s internal information. Implementing retrieval-augmented generations has two main benefits: it ensures that the model has access to the most current facts and that users have access to the model’s sources, ensuring that its claims can be checked for accuracy and ultimately trusted. RAG can help reduce, if not eliminate, the hallucination problem.
The maximum size of large language models’ (LLMs) input is limited and referred to as the “context window.” For GPT-3, the context window is set at 4000 tokens (approximately 3000 words), and since pricing is determined per token, incorporating more context into the model results in increased costs. However, the context window is continuously expanding, and in the latest GPT-4 versions, it has been extended to 8000 tokens (around 6000 words).
Generally, there are three ways to provide information to the Large Language Model (LLM): retrieving context from a larger document corpus, increasing the number of LLM calls (using chains), and supplementing with external sources.
Retrieval-based models for context windows commonly employ a question-answering pattern. They start by formulating a question, identifying a document in the corpus that might contain the answer, and incorporating this document or a portion of it into the context window. Afterward, they make a call to the Large Language Model (LLM) to answer the question. However, a significant limitation of this approach is its reliance on the retrieval system; if the required information is absent from the retrieved documents, the model may struggle to provide an answer.
Chaining sequencing language model calls involves using the output of one call as the input for another. One illustrative application is the process of summarizing a substantial corpus, which resembles a map-reduce approach. In this method, independent LLM calls are made to summarize individual documents, and subsequently, the summaries are summarized.
Building context for language models to answer questions can involve using a search engine or giving them access to APIs and outside tools. For instance, a Google Search chain (LangChain package) involves searching Google for an answer, getting the top result, and summarizing the content for the user. Examples of tools for language models include archive search, Python interpreters, and SQL query execution links.
Guiding Factors for Utilizing LLM in Your Business Projects
Accuracy Requirements
Incorrect project outputs can pose risks, incur costs, carry ethical implications, or result in user dissatisfaction. It’s essential to recognize that project expenses typically increase proportionally with accuracy requirements.
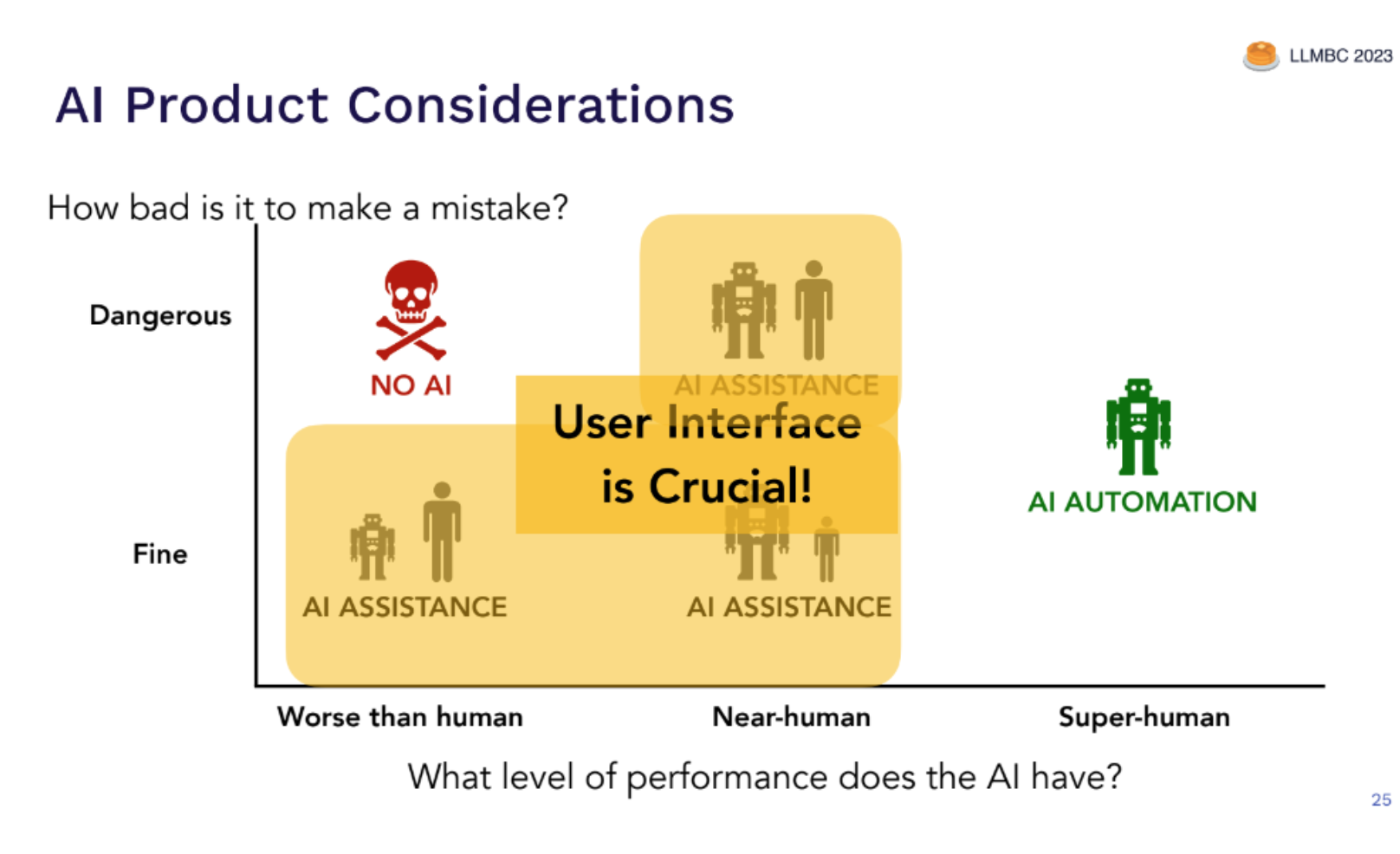
The experts recommended comparing metrics that assess the level of risk associated with mistakes made by an LLM-powered application to human performance on similar tasks. If the LLM’s performance falls below that of humans and mistakes carry significant risks, it may not be suitable for the application. Conversely, if the LLM demonstrates super-human performance, it could potentially replace human involvement. Various degrees of LLM-powered app assistance may be appropriate for performance levels in between.
Furthermore, if the LLM’s potential mistakes are worse than those made by humans, it should be controlled by humans. However, if the LLM’s performance closely aligns with human capabilities, it can expedite tasks. It’s important to note that, for most tasks, user involvement remains essential, making the user interface a critical component of the system.
Latency Requirements
Latency, defined as the time taken for a request to undergo processing and receive a response, is primarily shaped by two key factors: the specific model in use and the number of tokens being generated during the process. Trade-offs exist between the speed and the quality of content generated by different LLM models. For example, high-performance models like gpt-4 offer intricate but slower responses, and models like gpt-3.5-turbo provide faster responses but may be less precise. The majority of latency concerns for a particular model are centered around the token generation step. For instance, commonly used GPT models gpt-3.5-turbo exhibit latency times typically falling within the range of 10-20 seconds.
The ChatGPT playground enhances user experience by implementing streaming requests, allowing the model to return tokens as they become available rather than waiting for the entire token sequence to be generated. This adjustment does not affect the overall time to obtain all tokens but notably decreases the time it takes to receive the first token. This improvement is particularly beneficial for applications where showcasing partial progress or interrupting generation is a priority.
Privacy and Security
Implementing language models in production, including LLMs, presents various risks.
Data Leakage
Data leakage vulnerabilities can occur when LLMs accidentally reveal sensitive information, proprietary algorithms, or other confidential details through their responses. When using large language models, it’s common to provide some context or prompt to guide the model’s response. However, if the prompt contains sensitive information that should not be disclosed, there is a risk of leakage. The model might generate or infer sensitive details from the provided context and include them in its future outputs. Anything that you share with ChatGPT is retained and used for further model training. To protect clients’ privacy, companies should use techniques like data anonymization and differential privacy when processing data for the LLM to protect sensitive information.
Prompt Injection
Prompt injection is a security vulnerability that can exploit large language models (LLMs) by manipulating the input prompt text. This can lead to unintended or malicious outputs and poses various risks. Attackers could inject malicious code into the prompt, which the LLM may execute. This can result in data theft or the display of harmful content. For instance, a translation prompt could be altered to execute JavaScript code in the user’s browser. Also, attackers may inject commands into the prompt, which the LLM executes. This can result in taking control of the user’s device or causing the LLM to crash. Companies should use safeguards to prevent prompt injections. This includes securing APIs, controlling access to the model, and monitoring usage patterns for potential threats. Cyber security remains one of the major concerns with the broader implementation of AI technologies and them potentially falling into the hands of bad actors.
Possible Harmful Output
LLMs can sometimes generate inappropriate or harmful content. Companies should implement mechanisms to filter or moderate the model’s output to prevent negative consequences.
Process of the LLM-Powered Application Development
Planning and Project Setup
During the initial stages of project planning, it is crucial to pinpoint high-impact issues suitable for Language Model (LLM) applications, addressing challenges like product friction, automation of manual processes, and meaningful text generation.
Many successful real-world applications function as assistant tools, allowing users to review the generated output. Notable real-world applications include chatbots like ChatGPT and autocompletion tools such as GitHub Copilot and Grammarly, all utilized for tasks like auto-completion and grammatical error correction, with outputs subject to human review. Additionally, Google Search and Bing Search share the goal of providing summarized answers at the top of search result lists, while Google Translate specializes in translating text across over 100 languages.
In the process of setting up an LLM project, a crucial step involves engaging with stakeholders to define specific requirements and project goals. The key considerations include:
- Risk Assessment: Evaluate the level of risk associated with mistakes made by the LLM-powered application, recognizing that project expenses tend to increase proportionally with accuracy requirements.
- Latency Requirements: Assess the time taken to receive a response, defining latency requirements as an essential aspect of project planning.
- Data Privacy and Security: Give due consideration to data privacy and security, addressing the necessary measures and safeguards to protect sensitive information.
- Ethical Implications: Carefully evaluate ethical implications to ensure the project is conducted ethically and responsibly.
This collaborative effort with stakeholders helps align the project’s objectives with the expectations and needs of all involved parties.
LLM Application Stack
LLM applications are constructed with various key components, comprising:
- Foundation Model: Serving as the core, this component is pivotal, as it defines the performance of your LLM application.
- ML Infrastructure: This includes the provision of computing resources through cloud platforms or the company’s proprietary hardware.
- Additional Tools: Various supplementary tools, encompassing data pipelines, vector databases, orchestration tools, fine-tuning ML platforms, and model performance monitoring tools
We’ll provide a brief walkthrough of these components to enhance your understanding of the toolkit required for building and deploying an LLM application.
Selecting Foundation Model
Most companies use pre-trained LLM models because training such a model from scratch is a timely and very costly process that is beyond the capabilities of most companies. For example, it costs OpenAI approximately $100 million every time they train their model. Google’s Gemini model comes in different sizes, including a Nano size with less than 2 billion parameters, making it cheaper to train and easier to deploy on low memory devices. There are several pre-trained models available on the market. Here are several factors to consider when choosing a foundation model for your LLM application:
- Choose Between Proprietary and Open-Source Models for Your Language Model Needs. Proprietary models, owned by a single entity, are typically accessible for a fee. Examples include GPT models by OpenAI, Claude models by Anthropic, and Jurassic models by AI21 Labs. On the other hand, open-source models are generally available for free, although some may have usage limitations, such as being restricted to research purposes or specific company sizes for commercial use. Notable free-to-use language models include Llama models by Meta, Falcon models by the Technology Innovation Institute in Abu Dhabi and StableLM models by Stability AI. Proprietary models, typically more extensive and capable than open-source counterparts, allow interaction through API calls without the need for separate deployment servers. However, their code lacks transparency, posing challenges for debugging and troubleshooting. In contrast, open-source models receive fewer updates and less developer support. Deploying them on servers with expensive GPU cores for LLM processing is necessary. The key advantage of open-source models lies in the control over data flow, making them suitable for applications demanding high security.
- Choose the Size of the Model. When choosing a language model, various versions are often available, differing in the size of tunable parameters, training methods, and datasets used. For instance, GPT has versions like GPT-4 and GPT-3.5-turbo. The selection of a model size involves trade-offs between size, performance, and computational efficiency. Larger models, like GPT-4, are adept at knowledge-intensive tasks but come with higher computational costs and potential delays in response times. Consider these factors to strike a balance in meeting specific task requirements.
Set Up ML Infrastructure
The choice between proprietary and open-source models significantly influences the required ML infrastructure. Open-source models demand allocated resources for deploying and running Language Models (LLMs), with resource needs determined by the model’s size, complexity, intended tasks, and the scale of business activity. Various cloud platforms, such as Google Cloud Platform, Amazon Web Services, and Microsoft Azure, offer services facilitating LLM deployment with features that streamline the process. In contrast, proprietary models may not necessitate resources for deployment, but attention must be given to wrapping the application around model API calls.
Augmenting Processes With Tools
- Data Pipelines
In integrating your data with your Language Model (LLM) product, the data preprocessing pipeline becomes a vital component of your technology stack, resembling its role in the traditional enterprise AI stack. This pipeline includes connectors for data ingestion from various sources, a data transformation layer, and downstream connectors. Leading data pipeline providers, such as Databricks and Snowflake, simplify the process for developers to direct extensive and diverse natural language data, such as PDFs, PowerPoint presentations, chat logs, and scraped HTML, to a central point of access. This facilitates utilization by LLM applications, streamlining data management. - Vector Databases
Large language models face limitations in processing extensive documents, restricted to handling a few thousand words at a time. To overcome this constraint and effectively process large documents, vector databases are used. These databases store structured and unstructured data, like text or images, along with their corresponding vector embeddings. Vector databases play a crucial role in generating quick responses in scenarios demanding real-time user interaction, such as chatbots or virtual assistants. These databases, like Pinecone, and open-source options such as Chroma and SeMI, facilitate quick retrieval of relevant context or information represented as vectors, ensuring seamless engagement with users. - Orchestration Tools
When users submit queries to your Language Model (LLM) application, like customer service inquiries, the application must generate a sequence of prompts before presenting the query to the language model. The ultimate request to the language model usually consists of a developer-hardcoded prompt template, essential data fetched from external APIs, and pertinent documents obtained from the vector database. Orchestration tools from companies such as LangChain or LlamaIndex can enhance efficiency in this process, offering pre-configured frameworks for prompt management and execution.
Testing and Evaluation LLMs
Testing and assessing Language Models (LLMs) involve addressing two fundamental questions: the choice of data for testing and the selection of appropriate metrics for analysis. When developing LLMs, it is advisable to construct evaluation sets incrementally, starting from the early stages of model prototyping. To aid in the construction of evaluation sets, labeling tools like Label Studio, LabelBox, and Tagtog may be necessary.
The metrics used to evaluate language models largely depend on the availability of certain reference points. In cases where a correct answer exists, metrics such as accuracy can be employed. When a reference answer is accessible, it is more appropriate to utilize reference-matching metrics like semantic similarity and factual consistency. In situations where a prior answer is available, a different language model can be consulted to determine the superior response. If human feedback is at hand, it is crucial to assess whether the model’s answer incorporates this feedback effectively.
In cases where none of these options are applicable, it becomes necessary to verify the structural integrity of the output or request the model itself to assign a grade to the answer. While automated evaluation processes are desirable for expediting experimentation, it is important to acknowledge that manual checks continue to play an indispensable role in the evaluation of Language Models.
To help evaluate LLMs, tools like HoneyHive or HumanLoop have emerged.
Deployment and Monitoring
The deployment and monitoring of LLM-powered applications are critical steps in ensuring their effectiveness. Deploying these applications involves a process that requires careful planning, extensive testing, and a keen focus on user experience and data security. A successful deployment not only ensures seamless user interactions but also enhances the overall functionality of the business’s website. Integration can be approached in three ways: through API integration, plugin or module integration, or custom code integration.
Monitoring LLMs post-deployment is equally important. It entails assessing user satisfaction, establishing performance metrics such as response length, and identifying common issues that may arise in production. These issues can encompass problems related to the user interface, latency, accuracy of responses, verbosity in replies, and safeguarding against prompt injection attacks. There are tools for monitoring LLMs emerging, such as Weights & Biases, Whylabs, and HumanLoop.
To continuously enhance LLM performance, user feedback plays a pivotal role. By identifying and addressing recurring themes or issues based on user input, improvements to prompts can be made. The iterative process involves an “outer loop” where, after deploying the model into production, its performance in real user interactions is measured. Real-world data is then leveraged to refine the model, creating a data flywheel that drives continual improvement. This holistic approach ensures that LLM-powered solutions remain effective and responsive to evolving user needs.
Conclusion
Exploring Large Language Models (LLMs) reveals the transformative impact they can have across diverse industries. LLMs, such as GPT-4 and its successors, with their massive parameters, excel in understanding and generating human language, showcasing proficiency in tasks ranging from content generation to code understanding.
The importance of LLMs in Generative AI applications is underscored by their versatility, offering benefits such as natural language generation, code completion, and conversational capabilities. From content summarization to personalized experiences, LLMs contribute significantly to enhancing efficiency and accessibility in various domains.
As enterprises race to keep pace with AI advancements, identifying the best approach for adopting LLMs is essential. Foundation models can help jumpstart the development process. Using key tools and environments to efficiently process and store data and customizing models with business and domain-specific knowledge can significantly accelerate productivity and advance business goals.
In summary, LLMs represent a powerful tool for businesses seeking innovative Gen AI solutions. As technology advances, the responsible and strategic integration of LLMs holds the potential to revolutionize industries and enhance user experiences across a wide range of applications.




