The development of multimodal large language models (MLLMs) represents a significant leap forward. These advanced systems, which integrate language and visual processing, have broad applications, from image captioning to visible question answering. However, a major challenge has been the high computational resources these models typically require. Existing models, while powerful, necessitate substantial resources for training and operation, limiting their practical utility and adaptability in various scenarios.
Researchers have made notable strides with models like LLaVA and MiniGPT-4, demonstrating impressive capabilities in tasks like image captioning, visual question answering, and referring expression comprehension. However, these models must grapple with computational efficiency issues despite their groundbreaking achievements. They demand significant resources, especially during the training and inference stages, which poses a considerable barrier to their widespread use, particularly in scenarios with limited computational capabilities.
Addressing these limitations, researchers from Anhui Polytechnic University, Nanyang Technological University, and Lehigh University have introduced TinyGPT-V, a model designed to marry impressive performance with reduced computational demands. TinyGPT-V is distinct in its requirement of merely a 24G GPU for training and an 8G GPU or CPU for inference. It achieves this efficiency by leveraging the Phi-2 model as its language backbone and pre-trained vision modules from BLIP-2 or CLIP. The Phi-2 model, known for its state-of-the-art performance among base language models with fewer than 13 billion parameters, provides a solid foundation for TinyGPT-V. This combination allows TinyGPT-V to maintain high performance while significantly reducing the computational resources required.
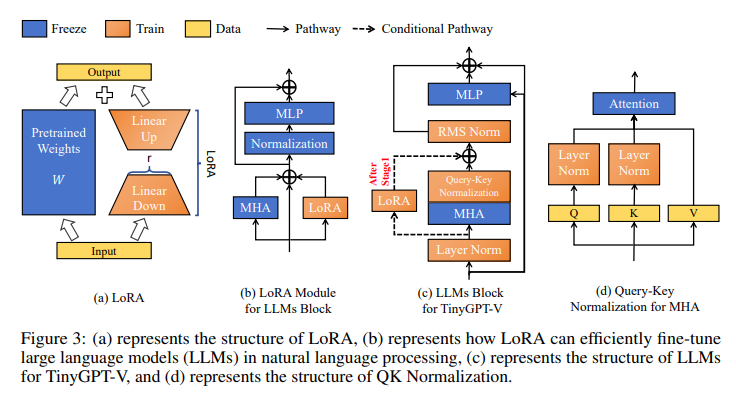
The architecture of TinyGPT-V includes a unique quantization process that makes it suitable for local deployment and inference tasks on devices with an 8G capacity. This feature is particularly beneficial for practical applications where deploying large-scale models is not feasible. The model’s structure also includes linear projection layers that embed visual features into the language model, facilitating a more efficient understanding of image-based information. These projection layers are initialized with a Gaussian distribution, bridging the gap between the visual and language modalities.
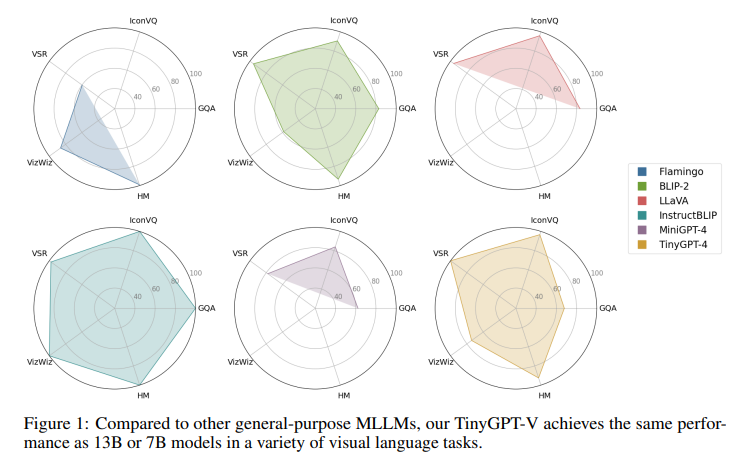
TinyGPT-V has demonstrated remarkable results across multiple benchmarks, showcasing its ability to compete with models of much larger scales. In the Visual-Spatial Reasoning (VSR) zero-shot task, TinyGPT-V achieved the highest score, outperforming its counterparts with significantly more parameters. Its performance in other benchmarks, such as GQA, IconVQ, VizWiz, and the Hateful Memes dataset, further underscores its capability to handle complex multimodal tasks efficiently. These results highlight TinyGPT-V’s high performance and computational efficiency balance, making it a viable option for various real-world applications.
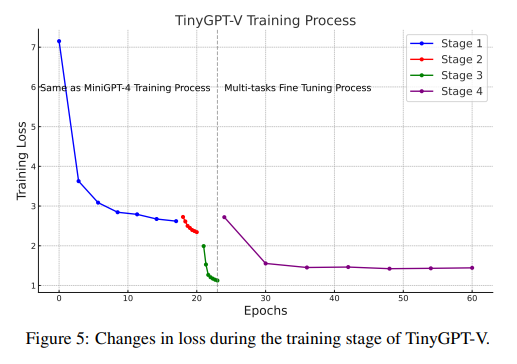
In conclusion, the development of TinyGPT-V marks a significant advancement in MLLMs. Effective balancing of high performance with manageable computational demands opens up new possibilities for applying these models in scenarios where resource constraints are critical. This innovation addresses the challenges in deploying MLLMs and paves the way for their broader applicability, making them more accessible and cost-effective for various uses.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.


 Free For Your Email")


