Think back to when you took a science class in high school or college. Introductory physics, for example. There was one textbook and, if you learned the material in the book, you got a high grade in the class. If you were super serious, you might read a second textbook that reinforced what was in the first book and might even have added a few new concepts. A third book wouldn’t have added much, if anything. Reading a 10th, 20th, or 100th textbook would surely have been a waste of time.
Large language models (LLMs or chatbots) are like that when it comes to absorbing factual information. They don’t need to be told 10, 20, or 100 times that Abraham Lincoln was the 16th President of the United States, Paris is the capital of France, or that the formula for Newton’s law of universal gravitation is
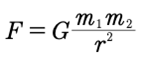
Training on larger and larger data sets might improve an LLM’s writing skills, in the same way that reading dozens of books in English classes might improve a student’s writing ability. But it will have little effect on an LLM’s ability to recite factual information. In fact, with the increasing pollution of the internet by disinformation promulgated by LLMs, the ability of LLMs to recite facts might actually worsen. A recent paper in Nature argued that, because the internet data that LLMs train on is increasingly dodgy computer-generated text, “indiscriminate use of model-generated content in training causes irreversible defects in the resulting models.”
Nature also recently published an article titled: “Larger and more instructable language models become less reliable” An article in the IEEE Spectrum agreed:
The prevailing methods to make large language models more powerful and amenable have been based on continuous scaling up (that is, increasing their size, data volume and computational resources) and bespoke shaping up (including post-filtering, fine tuning or use of human feedback). However, larger and more instructable large language models may have become less reliable.
The AI bubble has long been fueled by claims that artificial general intelligence (AGI) is within reach—just a few months or, at worst, a few years away. In an October 29 interview, Elon Musk said:
I certainly feel comfortable saying that it’s getting 10 times better per year… I think it will be able to do anything that any human can do possibly within the next year or two.
Never mind that we are not told what it is getting 10 times better at each year (raising money for startups?). OpenAI’s Sam Altman recently predicted the arrival of AGI in 2025. A little over a year ago, in October 2023, Blaise Agüera y Arcas and Peter Novig wrote a piece titled “Artificial General Intelligence Is Already Here.”
Some of this preposterous hype is hopelessly vague and obviously self-serving. Attempts to go beyond blah-blah and measure the increases in LLM capabilities are generally flawed. Gary showed that the graphs purportedly documenting “emergence” are an optical illusion created by using a logarithmic scale on the time axis and are, in fact, fully consistent with diminishing returns to scaling. A group of Stanford professors has shown that, “Via all three analyses, we provide evidence that emergent abilities disappear with different metrics or with better statistics, and may not be a fundamental property of scaling AI models.”
Our argument can also be illustrated with simple examples that require critical thinking beyond the rote recitation of recalled text. To take an example from economics, LLMs can recite formulas for calculating present values but they don’t understand how to use these formulas. In early January of this year, Gary asked OpenAI’s ChatGPT 3.5, Microsoft’s Bing with GPT-4, and Google’s Bard this question:
I need to borrow $47,000 to buy a new car. Is it better to borrow for one year at a 9 percent APR or for 10 years at a 1 percent APR?
None of these LLMs recognized that the answer to this question requires a present value calculation. Nor did they have the common sense to recognize that a loan with a 1% APR is a great deal and should be embraced for as long as possible. Gary wrote:
A human being living in the real world would immediately recognize that a 1 percent APR is an extremely attractive loan rate, particularly if it can be locked in for several years. No calculations would be needed to recognize the appeal of a 10-year loan with a 1 percent APR.
Instead, each LLM made a number of logical errors and miscalculations and, in the end, concluded that the 1-year loan at 9% was more attractive because the total payments (interest and principal) would be lower, completely ignoring the time value of money.
We have now revisited this question with OpenAI’s new and allegedly improved Preview-01 to see if the answer had improved. Nope. It still ignored the time value of money and recommended the 1-year 9% loan.
The core problem — that LLMs have no idea what words mean and cannot employ logical reasoning or even simple common sense — is not going to be solved by training on larger datasets. The answers might be slightly better written and some factual errors might have been corrected by human trainers. But scaling up is not going to get us to AGI, not now, not in 2 to 3 years, maybe never.
Even researchers who have every incentive to tout the reasoning abilities of LLMs have become critical. Six Apple researchers recently wrote that “current LLMs are not capable of genuine logical reasoning; instead, they attempt to replicate the reasoning steps observed in their training data.”
Recent information from careful analyses of OpenAI’s newest model, Orion, suggests that the promise of AI and even of significant improvements in AI is slipping away.
OpenAI’s next flagship artificial-intelligence model is showing smaller improvements compared with previous iterations…in a sign that the booming generative-AI industry may be approaching a plateau.
Similar stories are emerging from Google (“an upcoming iteration of its Gemini software is not living up to internal expectations”) and Anthropic (“has seen the timetable slip for the release of its long-awaited Claude model called 3.5 Opus”).
Even the founders of the venture capital firm Andreessen Horowitz admitted recently that “they’ve noticed a drop off in AI model capability improvements in recent years.” Co-founder Ben Horowitz said that a comparison of the differences between GPT-2.0, GPT-3 and GPT-3.5 models and the difference between GPT-3.5 and GPT-4 show that “we’ve really slowed down in terms of the amount of improvement.” Co-founder Marc Andreessen added that, two years ago, the GPT-3.5 model was “way ahead of everybody else…. Sitting here today, there’s six that are on par with that. They’re sort of hitting the same ceiling on capabilities.”
We have argued that revenue from corporate adoption of AI continues to be disappointing and, so far, pales in comparison to the internet revenue that sustained the dot-com bubble — until it didn’t. The growing recognition that there are fundamental challenges that make LLMs unreliable and that these are not going to be solved by increasingly expensive scaling are likely to hasten the popping of the AI bubble.





