In the previous article (linked below), we did a deep dive into the prompting-based pointwise, pairwise, and listwise techniques that directly use LLMs to perform reranking. In this article, we will take a closer look at some of the shortcomings of the prompting methods and explore the latest efforts to train ranking-aware LLMs. The article also describes several strategies to build effective and efficient LLM-based rerankers.

This article reviews recent research direction that directly prompts LLMs to perform ranking using pointwise, pairwise, or listwise techniques.

This article reviews some of the recent proposals from the research community to boost text retrieval and ranking tasks using LLMs.
Empirically, several studies have found that current LLMs do not fully understand the ranking task, potentially due to the lack of ranking awareness during the pre-training and fine-tuning procedures. Making LLMs more ranking aware in a data-efficient manner while maintaining their generality for other tasks, is a challenging research direction.
The previous article highlighted several issues with prompting-based approaches. Pointwise ranking strategies do not work for generation APIs (common with closed-source LLMs, like GPT-4). Pointwise ranking also requires the model to output calibrated scores so that they can be used for comparisons in sorting. This is difficult to achieve across promptings, and also unnecessary because ranking only requires relative ordering. The pairwise approach tends to perform best because LLMs do have a sense of pairwise relative comparisons. But comparing all possible pairs can be computationally prohibitive. Listwise ranking tasks have shown to be the most difficult for LLMs, especially for smaller and even moderate-sized models. Context size limits make it impossible to include all possible candidate documents in the prompt. Also, LLMs may only output a partial list of documents, may output the same document more than once, produce irrelevant outputs, or may even refuse to perform the ranking task.
Various studies have shown that language models struggle to robustly access and use information in long input contexts for reranking tasks. Specifically, the performance of language models is significantly affected by the position of relevant information and the relative ordering of candidate documents in the input context.
-
Liu et al. conducted an empirical investigation using multi-document question-answering to understand how well language models with large context windows (e.g., 4096, 32K, and even 100K tokens) use their input context. They found that the language model performance is highest when relevant information/document occurs at the very beginning (primacy bias), or end (recency bias) of the input context, and performance significantly degrades when the models must access and use information in the middle of their input context.
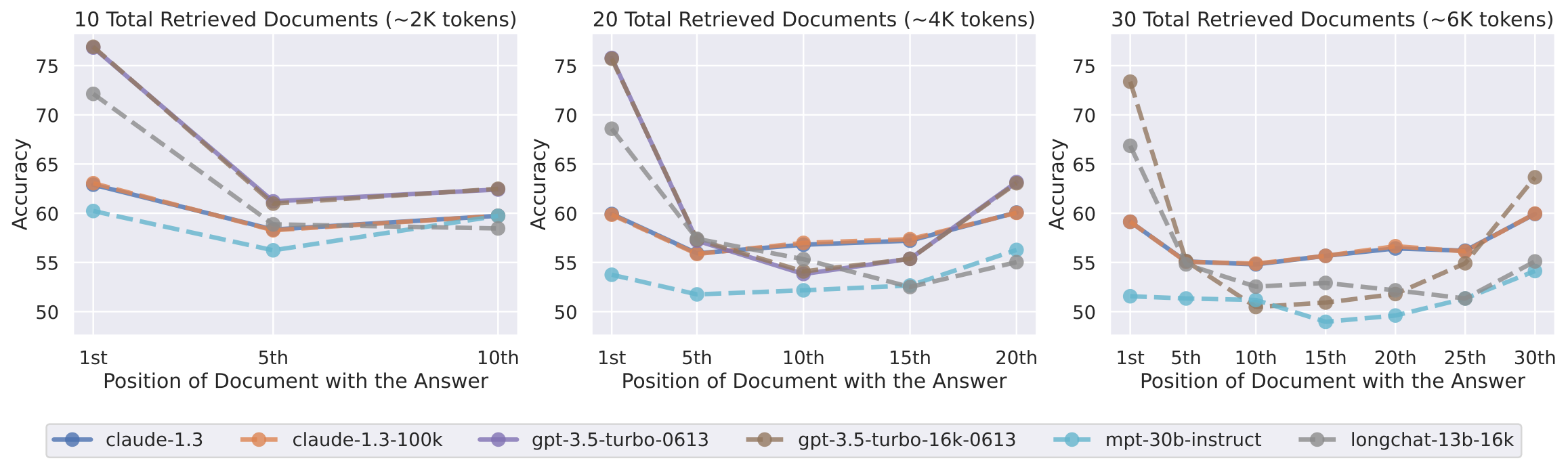
the effect of changing the position of the relevant document on multi-document question answering performance -
Similarly, Wang et al. looked into the LLMs-as-evaluator paradigm and found that LLMs suffer from positional bias, i.e. they prefer the response in the specific position. Their study showed that GPT-4 tended to prefer the item in the first position, while ChatGPT preferred the response in the second position. Also, swapping the slots of the two responses and querying LLM twice will most likely produce conflicting evaluation results. Consequently, the ranking quality can easily be hacked to make one model appear superior to others, for example, Vicuna-13B could beat ChatGPT on 66 over 80 tested queries.
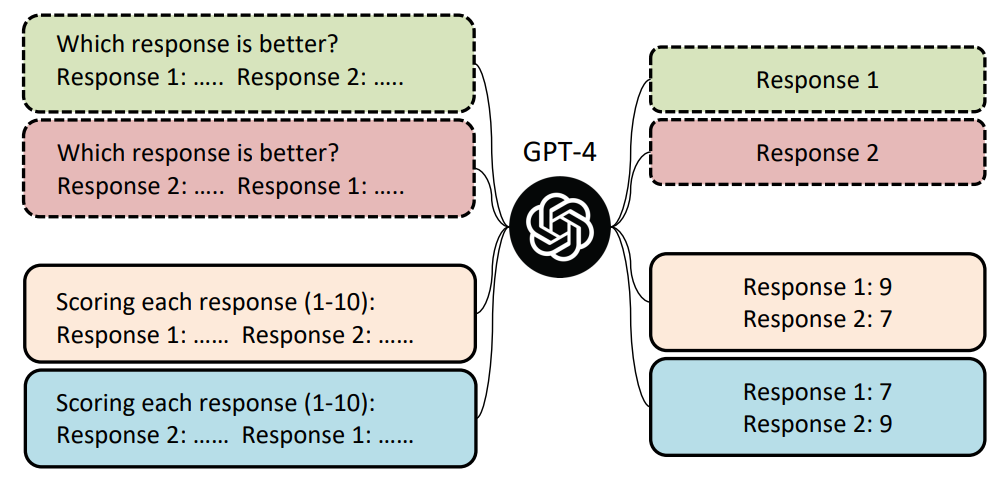
Merely swapping the presentation order of candidate resposnses could lead to overturned comparison results As shown below, when swapping the order of two responses, GPT-4 is more likely to produce conflicting results when the score gap between the two responses is smaller.
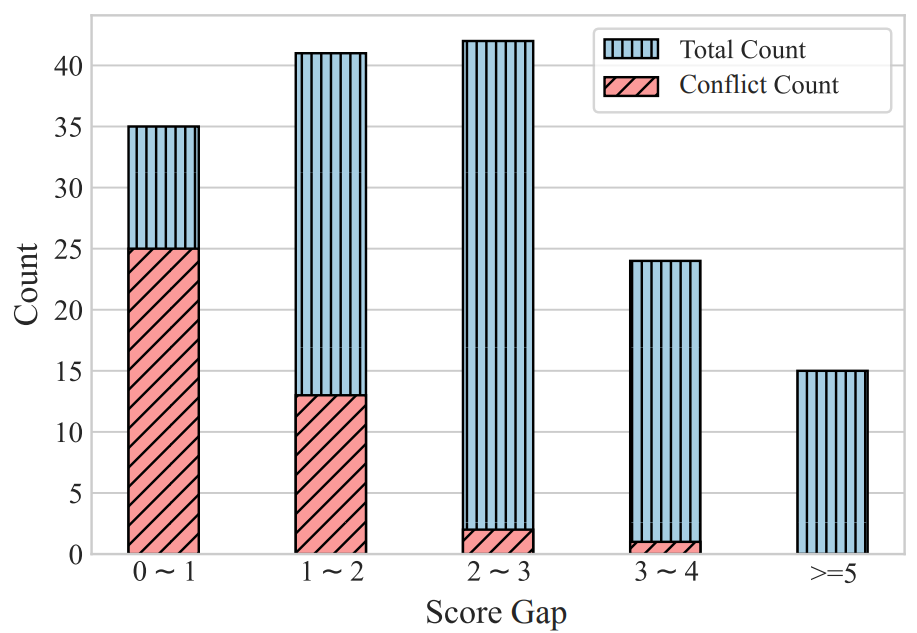
The conflict rate is negatively correlated with the score gap between the two responses. -
Lu et al. studied the effect of input ordering on in-context learning performance and found that the right sample order can make as much of a difference as the right template. The performance variation of different permutations was shown to be a big issue, especially for smaller models. While increasing the model size helped, it still didn’t resolve the problem. Also, there was no common denominator between the performant sample orders and performant prompts were not transferable across models.
-
Tang et al. conducted a passage reranking task analysis and concluded that different positional biases exist in reranking LLMs, varying by model and dataset. For example, in their experiments, GPT-3.5 did not focus well on the items past the fifteenth.
Liu et al. conducted an empirical study to understand why the language models struggle to robustly access and use information in their input context. Their findings with respect to the evaluated aspects were as follows.
- Model Architecture: The authors compared the commonly used decoder-only models with encoder-decoder models. When encoder-decoder models (Flan-T5-XXL, Flan-UL2) are evaluated on sequences that are shorter than their encoder’s training time maximum length, they are relatively more robust to changes in the position of the relevant information in their input context. However, when these models are evaluated on sequences longer than those seen during their training (a feat possible due to relative positional embedding usage), their performance begins to degrade. The authors hypothesize that encoder-decoder models may make better use of their context windows because their bidirectional encoder allows processing each document in the context of future documents, potentially improving relative importance estimation between documents, whereas decoder-only models may only attend to prior tokens.
- Query-Aware Contextualization: When the query is placed after the documents in the input context, decoder-only models cannot attend to the query tokens when contextualizing documents, since the decoder-only models can only attend to prior tokens at each timestep. In their experiments, placing the query before the documents dramatically improves performance on a subset of retrieval tasks.
- Effect of Instruction Fine-Tuning: After their pre-training, instruction fine-tuned models undergo supervised fine-tuning on a dataset of instructions and responses. The task specification and/or instruction is commonly placed at the beginning of the input context in supervised instruction fine-tuning data, which might lead these instruction fine-tuned models to place more weight on the start of the input context.
- Model Size: The authors also found that the “lost in the middle” phenomenon only appeared in sufficiently large language models. For example, the 7B Llama-2 models were solely recency biased (similar to the recency bias found in non-instruction fine-tuned language models), while the 13B and 70B models exhibit the “lost in the middle” problem. Additionally, Llama-2 supervised fine-tuning and reinforcement learning from human feedback procedure slightly mitigates the position bias in smaller models.
In this section, we take a look at some of the recent proposals to alleviate the impact on ranking effectiveness stemming from the sensitivity to the order of candidates in the input context.
-
Wang et al. proposed a calibration framework to alleviate position bias and achieve a more reliable and fair evaluation result.
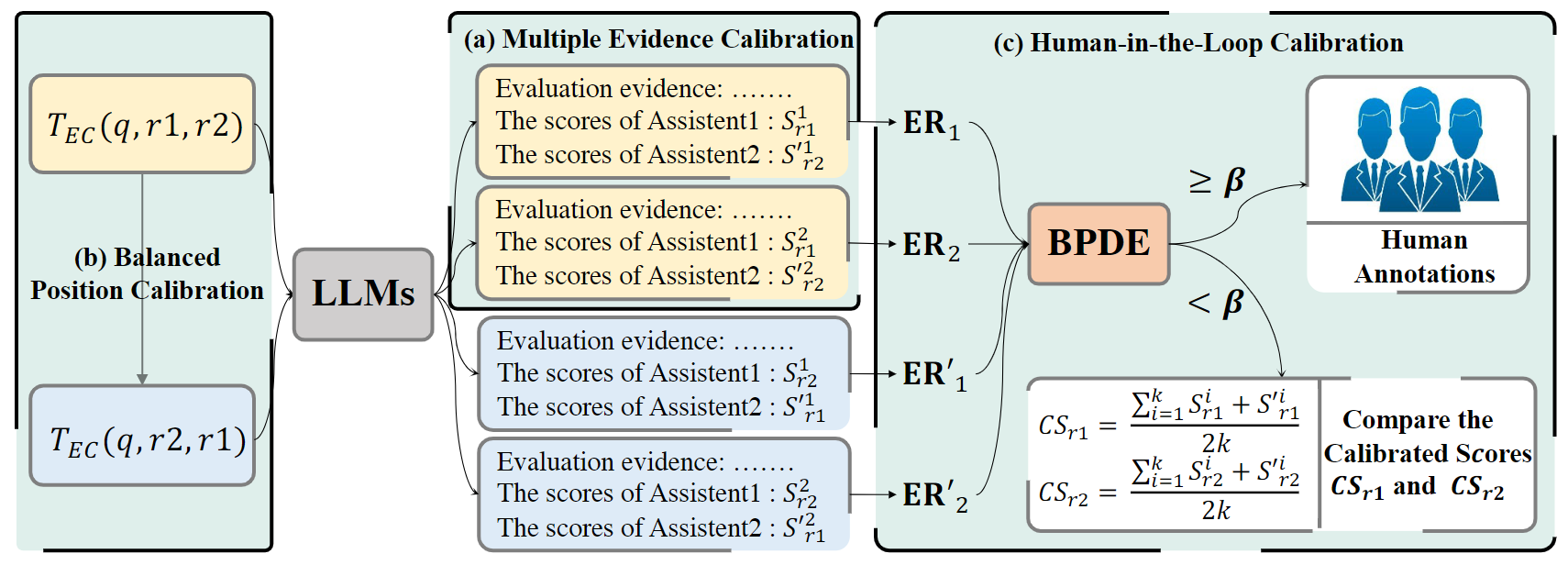
Calibration framework with three calibration methods Their calibration framework employs three simple strategies:
- Multiple Evidence Calibration (MEC): The authors design an evidence calibration (EC) evaluation template $T_{EC}(q, r_1, r_2)$ that requires the model to generate the explanations (“evaluation evidence”) first and then give the score. In this way, the score can be calibrated with the evaluation evidence. Next, they sample $k$ EC scores ${S_{r_1}^1,…,S_{r_1}^k}$ and ${S_{r_2}^{‘1},…,S_{r_2}^{‘k}}$ for responses $r_1$ and $r_2$, where $S_{r}$ and $S_{r}^{’}$ denote the scores of the response $r$ at the first and second positions respectively.
- Balance Position Calibration (BPC): An additional $k$ scores are calculated by swapping the two responses in each example, such as creating a query prompt $T_{EC}(q,r_2,r_1)$ along with the original query prompt $T_{EC}(q,r_1,r_2)$. The final calibrated scores of the two responses are the corresponding averages of the $2k$ scores.
- Human-in-the-Loop Calibration (HITLC): The authors introduce an entropy-based metric, the Balanced Position Diversity Entropy (BPDE) score, to find examples requiring auxiliary human calibration based on the evaluation results of the MEC and BPC. This strategy essentially measures the difficulty of each example and seeks human assistance when needed.
-
Tang et al. apply the shuffle-aggregate paradigm of the self-consistency framework to the decoding step for listwise-ranking LLMs to achieve permutation invariance. In their “Permutation Self-Consistency” strategy, the list of candidates is shuffled to curate a diverse set of rankings. Each of these output rankings has positional bias, but mistakes are expected to differ among the outputs because of the input order randomization. Then the central ranking closest in Kendall tau distance to all the sampled rankings is computed, which marginalizes out the association between individual list order and output rankings. The authors provide a theoretical proof of true convergence assuming there always exists some random pair of items that are correctly ranked among randomly ordered observations. This method incurs additional financial costs due to multiple LLM calls, however, the latency hit can be minimized by making these calls in parallel.
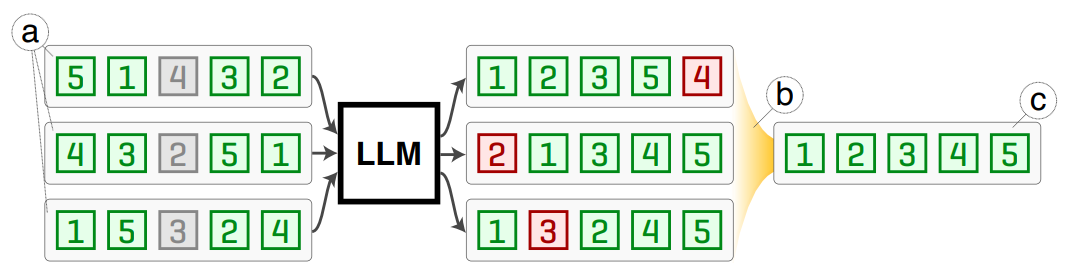
Permutation Self-Consistency Process -
Lu et al. proposed a probing method to identify the performant order of candidates in the input context under the few-shot setting. First, they construct a probing set by considering every possible permutation of the candidate items as a set of candidates. Then they use an entropy-based probing metric to calculate the average prediction entropy per data point. The entropy score is then used to rank the prompt ordering by performance.
Approaches that leverage prompt learning for LLM-based reranking have demonstrated promising effectiveness. However, it is difficult for them to outperform baseline reranker trained and/or fine-tuned on benchmark datasets. Some of the recent prompting-based methods rely on giant, blackbox, commercial LLMs like GPT-4, which has concerns around transparency, reproducibility, and cost constraints. These methods also run into issues like sensitivity to input order and often heavily rely on multiple decoding passes, and intricate prompt engineering. They also do not exploit available human judgments, such as MS MARCO, and do not allow joint reranker-retriever optimization.
Supervised ranking models based on PLMs demonstrate the current state-of-the-art performance. However, these approaches require a large amount of training data in the form of (query, relevant document) pairs for fine-tuning. Generally, these models can be classified based on their language model structure:
- Encoder-only: Models like monoBERT formulate the input as:
[CLS] query [SEP] document [SEP]. The[CLS]representation generated by the model is fed into a linear layer to compute the relevance score. - Encoder-Decoder: Models like monoT5 and RankT5 formulate their input as:
Query: query Document: document Relevant:into the encoder. The probability of a “True” token, generated by the decoder, serves as the relevance score for a text pair. - Decoder-only: Unidirectional attention-based models described in the next section, such as RankLLaMA, input a prompt containing the query and document pair and utilize the last token representation as the basis for text pair relevance.
Finally, there is still a noteworthy disparity between the training objective of LLMs, which typically centers around next token prediction and the objective of evaluating query-document relevance. Hence, off-the-shelf LLMs do not fully understand ranking formulations. This section highlights some of the recent efforts towards developing ranking-aware LLMs.
-
In RankGPT, Sun et al. distilled the ranking capabilities of ChatGPT (gpt–3.5–turbo) into a small specialized model using a permutation distillation scheme. The authors randomly sampled 10K queries from the MS MARCO training set, and each query was retrieved by BM25 with 20 candidate passages. The permutations predicted by ChatGPT are directly used as the target and are distilled into a student model (a cross-encoder model based on DeBERTa-large and a LLaMA-7B model was used) using a RankNet-based distillation objective. Their student model (435M) was able to monoT5 (3B) model. The authors claim that even with a small amount of ChatGPT-generated data, the specialized student model can outperform strong supervised systems, while also surpassing ChatGPT’s reranking performance. The code to reproduce RankGPT results is available on GitHub.
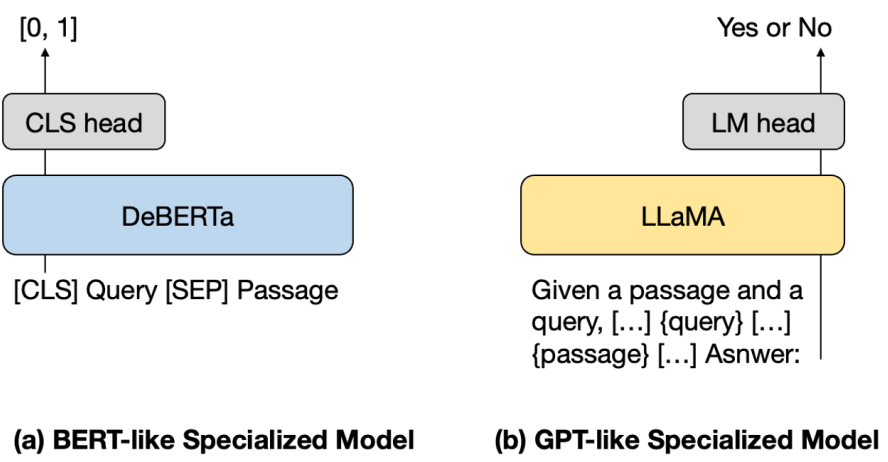
Two types of specialized models used in the study -
The authors of RankGPT also published another instruction distillation method that distilled the prediction of pairwise ranking with computationally demanding instruction (teacher instruction) to the efficient pointwise method but with simpler instruction (student instruction). The authors argue that generally pointwise ranking is more efficient but it compromises effectiveness. On the other hand, both listwise and pairwise ranking methods suffer from efficiency issues. Listwise ranking incurs exponential time complexity of the Transformer with respect to the input length, while pairwise ranking involves $O(n^2)$ calls to LLMs when it pairs every document with every other document. Their distillation process led to an increase in efficiency between 10 and 100x and up to 40% enhanced performance for the open-sourced FLAN-T5 LLM during the inference stage. The distilled FLAN-T5-XL model also surpassed monoT5-3B on evaluated benchmarks.
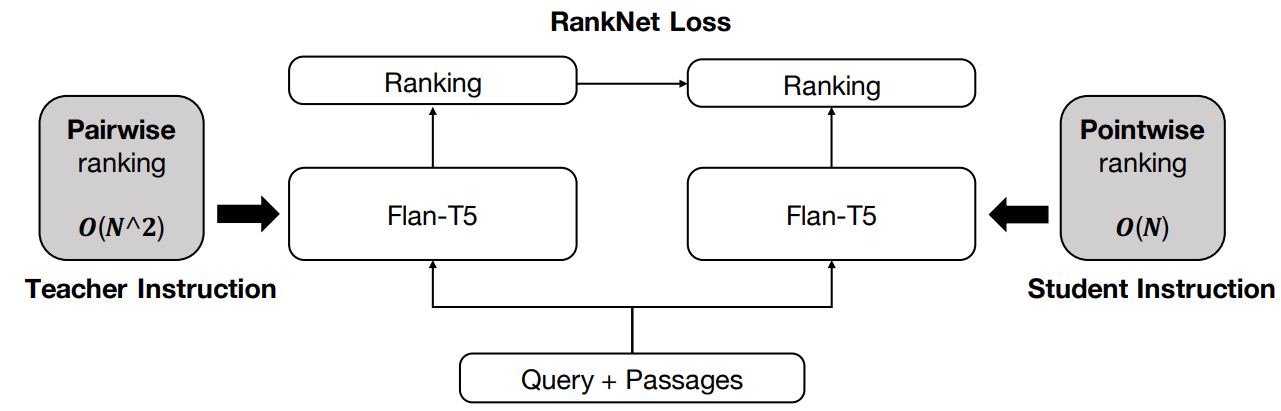
Instruction distillation to distill the abilities harvested from complex instruction techniques into a model that is more efficient with simple instruction techniques The code to reproduce instruction distillation work is available on GitHub.
Pointwise Ranking Prompt for InstructDistill
Question: Given a query “{{query}}”, Is the following passage relevant to the query?
Passage : {{passage}}
If it is relevant answer Yes, else answer No.
Answer:Pairwise Ranking Prompt for InstructDistill
Question: Given a query “{{query}}”, which of the following two passages is more relevant to the query?
passage A: {{passage_A}}
passage B: {{passage_B}}
Output the identifier of the more relevant passage. The answer must be passage A or passage B.
Answer: -
Pradeep et al. presented RankVicuna, an open-source LLM capable of performing zero-shot listwise reranking. The authors used the Vicuna model, instruction fine-tuned from Meta’s LLaMA-v2, as the student model trained on ranked lists generated by RankGPT-3.5 serving as the teacher model. To generate the training data, the authors randomly sampled 100K queries from the MS MARCO v1 passage ranking training set and retrieved 20 candidates using BM25. These 20 candidates were passed into RankGPT-3.5 to generate teacher orderings that were then distilled down to the student model, RankVicuna. To increase the model’s robustness to complex reordering tasks, the authors also included the shuffled input order along with the original BM25 input ordering. The effectiveness of RankVicuna (7B) is on par with RankGPT-3.5 (175B). RankVicuna codebase is accessible on GitHub.
Input Prompt for RankVicuna (prepended with Vicuna’s system description)
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user’s questions.
USER: I will provide you with {num} passages, each indicated by a numerical identifier []. Rank the passages based on their relevance to the search
query: {query}.[1] {passage 1}
[2] {passage 2}
…
[{num}] {passage {num}}Search Query: {query}.
Rank the {num} passages above based on their relevance to the search query. All the passages should be included and listed using identifiers, in descending order of relevance. The output format should be [] > [], e.g., [4] > [2]. Only respond with the ranking results, do not say any word or explain.
-
The authors of RankVicuna also proposed a 7B parameter Zephyr$_{\beta}$-based, state-of-the-art open-sourced RankZephyr model for listwise zero-shot reranking. Similar to RankVicuna, they first trained the RankZephyr model using teacher orderings ranked from RankGPT-3.5. Next, they sampled 5K queries from the original 100K sampled queries (due to cost constraints) and further trained the RankZephyr model leveraging RankGPT$_4$ as the teacher. The authors also address the fixed training window size limitation in RankVicuna by sampling a subset of passages ($\le 20$) and training the model with variable window sizes. RankZephyr improves over the pointwise RankLLaMA model, closes the effectiveness gap with RankGPT$_4$ and in some cases also surpasses the proprietary model.
Input Prompt and sample generation for RankZephyr
<|system|>
You are RankLLM, an intelligent assistant that can rank passages based on their relevancy to the query.
<|user|>
I will provide you with {num} passages, each indicated by a numerical identifier []. Rank the passages based on their relevance to the search query: {query}.[1] {passage 1}
[2] {passage 2}
…
[{num}] {passage {num}}Search Query: {query}.
Rank the {num} passages above based on their relevance to the search query. All the passages should be included and listed using identifiers, in descending order of relevance. The output format should be [] > [], e.g., [4] > [2]. Only respond with the ranking results, do not say any word or explain.
<|assistant|>Model Generation: [9] > [4] > [20] > . . . > [13]
-
Ma et al. proposed a zero-shot multi-stage ranking pipeline composed of a dense retriever (RepLLaMA) and a point-wise reranker (RankLLaMA), both based on fine-tuning the latest LLaMA model using the MS MARCO datasets.
RepLLaMA follows the bi-encoder dense retriever architecture but with the backbone model initialized with LLaMA. An end-of-sequence token
</s>is appended to the input query and document to form the input sequence to LLaMA, and the corresponding representation for this token is used as the representation of the input sequence, which can either be a query or a document. Both the models take the first 2048 tokens as input, which covered about 77% of the documents in the corpus used by the authors. Relevance is computed in terms of dot product and the model is optimized end-to-end using InfoNCE loss.RankLLaMA takes a query and a candidate document as input and generates a score that indicates the relevance of the document to the query. This model is also optimized by contrastive loss, and the hard negatives are sampled from the top-ranking results from the retriever. Being a pointwise reranker, RankLLaMA can rerank candidate passages in parallel. Both models demonstrate superior effectiveness in in-domain and zero-shot evaluations. Model checkpoints for this study are available on HuggingFace.
-
In RankingGPT, Zhang et al. proposed a supervised training strategy to improve LLM ranking capability. First, they construct a large-scale dataset of weakly supervised text pairs using web resources (using query-document pairs such as (title, body), (title, abstract), (post, comment), (entity, description), etc.) to continually pretrain the model and imbue a nuanced understanding of text relevance. The model is trained with a next (query) token prediction task with context provided by the documents. To further enhance the performance, the authors employ a supervised fine-tuning stage using the MS MARCO training set and contrastive learning. A ranking loss is used to help the model effectively discriminate between positive and negative instances.
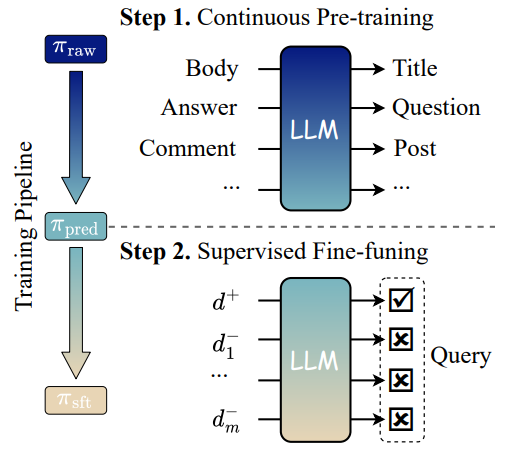
RankingGPT: two-stage training paradigm The authors experiment with LLMs of different types and sizes: BLOOM (560M-7B), LLaMA-7B, Qwen-7B, Baichua-7B, and show consistent improvements over the baseline versions of the models, and other models like MonoT5 and RankLLaMA. The authors will release the source code and fine-tuned model on GitHub.
- Use Variable Sizes for Sliding Window: In RankZephyr, Pradeep et al. showed that a listwise-ranking LLM trained with a fixed window size could fail to generalize to an arbitrary number of candidates within the maximum input token size. To address this shortcoming, they fine-tune RankZephyr with variable window sizes by randomly choosing a subset of passages ($\le 20$) to add to the input context.
- Relevance Can Be More Nuanced than Binary: Relevance generation reranking methods choose from binary relevance labels like “Yes” and “No” and use the prediction likelihood of these answers to derive the ranking score. But some documents may not be primarily intended to answer the query, but still contain helpful information. Zhuang et al. proposed incorporating intermediate fine-grained relevance labels, such as “Highly Relevant”, “Somewhat Relevant”, and “Not Relevant”, into the prompt to help LLM develop a more nuanced understanding of relevance. The intuition is that the intermediate relevance labels will help LLM distinguish partially relevant documents from fully relevant or fully irrelevant documents. To avoid using relevant labels with potentially ambiguous order, one can also employ a rating scale, such as a relevance scale from 0 to 4.
Different prompting strategies for relevance generation LLM rankers - LLMs Fine-Tuned for Ranking Might Lose Their Generalization Ability: Zhang et al. conducted a perplexity analysis before and after fine-tuning LLMs for reranking. Their experiments showed that RankLLaMA’s perplexity increased significantly, despite using fine-tuning based on LoRA with relatively small trainable parameters. This indicates that the model lost some of its generalization ability, which is the most valuable ability of LLMs.
- Select High-Performing Few-shot Demonstrations: Some researchers have shown that the few-shot reranking performance varies drastically depending on the demonstrations included in the prompt. Also, increasing the number of demonstrations does not necessarily help. Following this, they proposed methods to algorithmically select high-performing demonstrations to include in the prompt.
-
Li et al. proposed the LENS (filter-then–search) method to filter the dataset to obtain informative in-context examples individually. First, they filter the dataset using an “informativeness score”, and then use a diversity-guided example search method that iteratively refines and evaluates the selected examples to find the supporting examples that can fully depict the task.
-
Drozdov et al. proposed a difficulty-based selection (DBS) method to find challenging, i.e. low likelihood demonstration to include in the prompt. The authors propose to estimate difficulty using demonstration query likelihood (DQL): $DQL(z) \propto \frac{1}{\lvert q^(z) \rvert} \log P(q^(z) \lvert d^(z))$, and then selecting the demonstrations with the lowest DQL.
-
- Current IR Datasets Are Insufficient for Supervised Listwise Ranking: Zhang et al. found that the current IR training datasets, like MS MARCO, were constructed to train pointwise rerankers in a supervised fashion and yielded worse results than using data generated by BM25 when training pointwise rerankers. The performance of listwise rerankers increases linearly with training data ranking quality, and this relationship hasn’t plateaued yet. The authors call for future work on building human-annotated datasets purpose-designed for listwise ranking.
- Data Contamination May Cause Performance Overestimation: LLMs are often trained with a large amount of data crawled from the internet, which makes it very hard to know whether data from a specific benchmark was used to train the LLM. Since some of the commonly used IR benchmarks were also gathered years ago, the existing LLMs may already possess the knowledge of these datasets, including the benchmark test sets. However, the reranking models are expected to possess the capability to comprehend, deduce, and rank knowledge that is inherently unknown to them. To address this, Sun et al. constructed a test set, called NovelEval, that is continuously updated to ensure that the questions and passages have likely not appeared in the training data for LLMs. Both RankGPT and RankZephyr reported their performance on NovelEval.
- Impact of the First-Stage Retrieval: Several studies have confirmed that first-stage retrieval has a substantial impact on the overall effectiveness of the LLM reranker. Both the choice of the retrieval model and the number of candidates considered for reranking are crucial. For example, Pradeep et al. show that as the first-stage effectiveness increases, additional improvement from prompt-based reranker LLM decreases. Their reranker led to larger improvements when used with the top 100 BM25 candidates compared to candidates from SPLADE++ EnsembleDistil. Comparison between reranking the top 20 versus the top 100 candidates shows that processing a larger pool generally leads to larger improvements. The same study also shows that data augmentations, such as shuffling the input order of documents and permuting the generation orders provided by the teacher model led to more effective results.
There has been a growing interest in leveraging the language understanding and reasoning capabilities of LLMs in the information retrieval domain. In the previous article, we learned the prompting-based techniques to exploit LLMs as text rerankers. In this article, we looked closer at associated challenges and some of the potential improvements that can be done to make these methods more ranking-aware. The article also described the latest research work that bridges the gap between relevance ranking and the training objectives of LLMs. The article ended with a few additional learnings and takeaways from these works.



