For businesses, investors, and even curious individuals, real-time insights into the housing market can be invaluable. Redfin, a prominent player in the real estate sector, offers a mine of such data, spanning across more than 100 markets in both the United States and Canada. With a commendable 0.80% market share in the U.S. (Wikipedia), as gauged by the number of units sold, and boasting a network of approximately 2,000 dedicated lead agents, Redfin stands as a significant source of real estate intelligence.

In this blog, we will see how we can scrape data from Redfin using Python, further, I will show you how you can scale this process.
Let’s start!!
Collecting all the Ingredients for Scraping Redfin
Assuming that you have already installed Python 3.x on your machine and if not then please install it from here. Once this is done create a folder in which we will keep our Python scripts.
mkdir redfin cd redfin
Once you are inside your folder install these public Python libraries.
- Requests– This will be used for making the HTTP connection with redfin.com. Using this library we will install the raw HTML of the target page.
- BeautifulSoup– Using this we will parse the important data from the raw HTML downloaded using the requests library.
pip install requests pip install beautifulsoup4
Now create a python file inside this folder where you can write the script. I am naming the file as redfin.py.
With this our project setup is complete and now we can proceed with the scraping.
What are we going to scrape?
In this tutorial, we are going to scrape two types of pages from redfin.com.
- Redfin Search Page
- Redfin Property Page
Scraping Redfin Search Page
It is always a great practice to decide in advance what data you want from the page. For this tutorial, we are going to scrape this page.
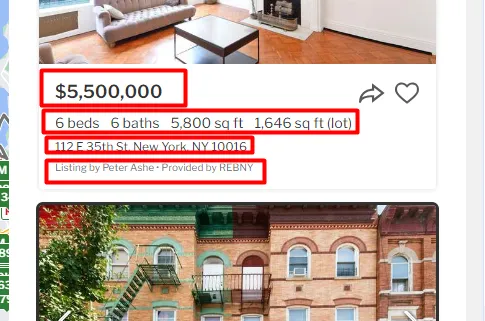
Download Raw HTML from the Page
Our first task would be to download the raw HTML from the target web page. For this, we are going to use the requests library.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
target_url="https://www.redfin.com/city/30749/NY/New-York/filter/status=active"
resp = requests.get(target_url,headers=head,verify=False)
print(resp.status_code)
First, we imported all the libraries that we installed earlier. Then I declared one empty list and one empty object.
The head variable is a dictionary containing the User-Agent header. The target_url variable contains the URL of the webpage to be scraped.
The requests.get function is used to send an HTTP GET request to the specified URL (target_url). The headers parameter is set to include the User-Agent header from the head dictionary. The verify=False parameter disables SSL certificate verification. The response object (resp) contains the server’s response to the request.
Once you run this code and see a 200 on the logs then that means you have successfully scraped the target web page.
Now, we can parse the data using BS4.
Parsing the Raw HTML
BeautifulSoup will now help us extract all the data points from the raw HTML downloaded in the previous section. But before we start coding we have to identify the DOM location of each element.
We will use the Chrome developer tool to find the DOM location. If you inspect and analyze the design of the page then you will find that all the property box is inside the div tag with the class HomeCardContainer. So, first, we should find all these elements using find_all() method of BS4.
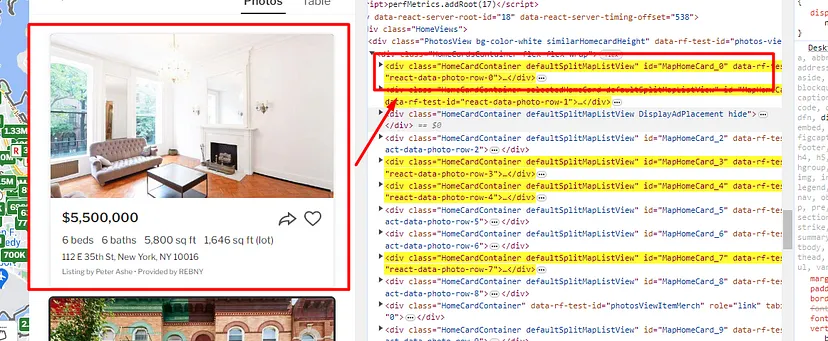
soup=BeautifulSoup(resp.text,'html.parser')
allBoxes = soup.find_all("div",{"class":"HomeCardContainer"})
The BeautifulSoup constructor is used to create a BeautifulSoup object (soup). The find_all method of the BeautifulSoup object is used to find all HTML elements that match the class HomeCardContainer.
allBoxes is a list that contains all the property data elements. Using for loop we are going to reach every property container and extract the details. But before we write our for loop let’s find the DOM location of each data point.
Let’s start with the property price.
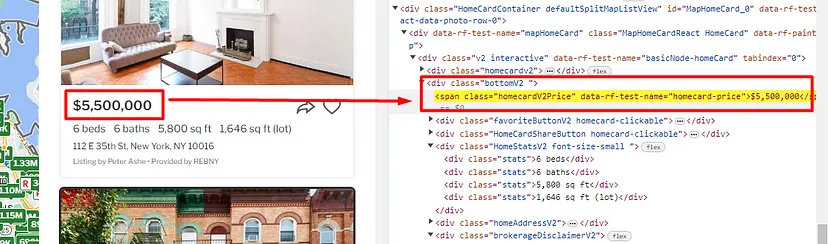
Once you right-click on the price you will see that the price is stored inside the span tag with the class homecardV2Price.
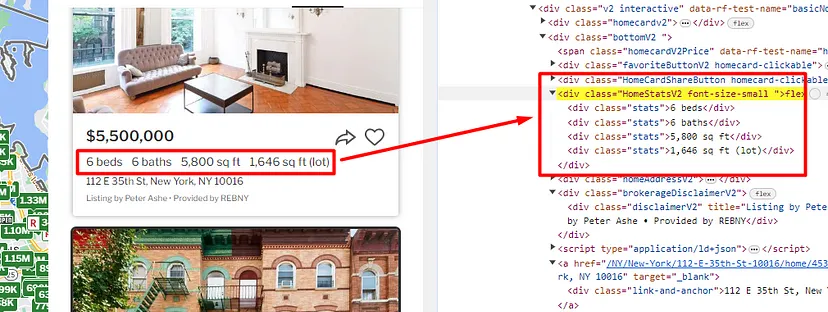
Similarly, the configuration of the property can be found inside the div tag with class HomeStatsV2.
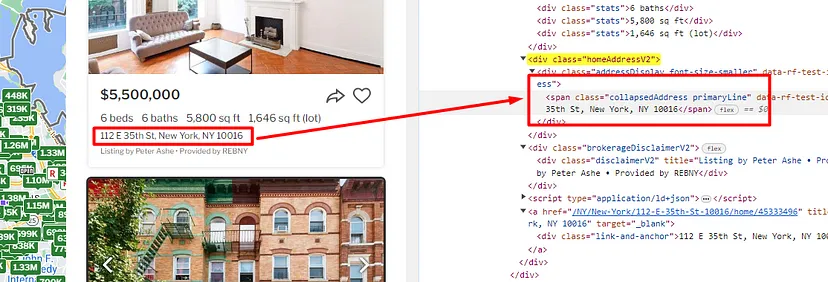
Agent/Broker name can be found inside the div tag with the class brokerageDisclaimerV2.
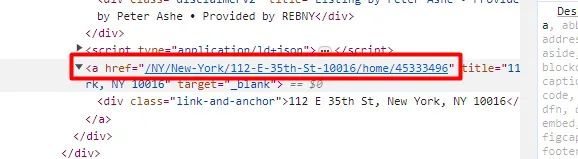
Individual property links can be found inside the a tag. This a tag is the only a tag inside each property container.
for box in allBoxes:
try:
o["property-price"]=box.find("span",{"class":"homecardV2Price"}).text.strip()
except:
o["property-price"]=None
try:
o["property-config"]=box.find("div",{"class":"HomeStatsV2"}).text.strip()
except:
o["property-config"]=None
try:
o["property-address"]=box.find("div",{"class":"homeAddressV2"}).text.strip()
except:
o["property-address"]=None
try:
o["property-broker"]=box.find("div",{"class":"brokerageDisclaimerV2"}).text.strip()
except:
o["property-broker"]=None
try:
o["property-link"]="https://www.redfin.com"+box.find("a").get('href')
except:
o["property-link"]=None
l.append(o)
o={}
print(l)
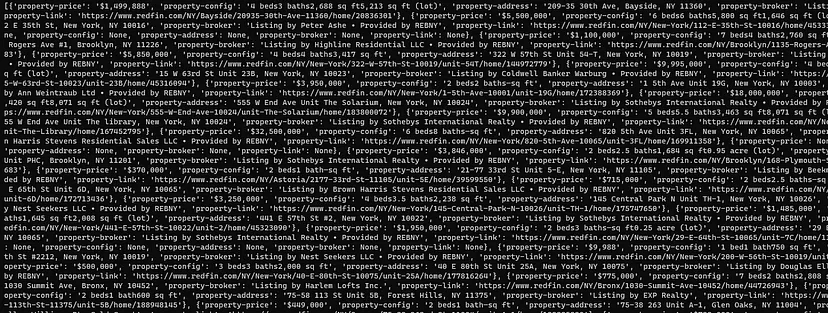
For each home card container, it extracts specific pieces of information, such as property price, configuration, address, broker details, and a link to the property.
for loop iterates through each element (box) in the list of home card containers. For each piece of information (property price, configuration, address, broker, link), a try block attempts to find the corresponding HTML element within the current home card container (box). If successful, it extracts the text content, strips leading and trailing whitespaces, and assigns it to the corresponding key in the dictionary (o). If the extraction fails (due to an attribute not being present or other issues), the except block sets the value to None.
After extracting information from the current home card container, the dictionary o is appended to the list l. Then, the dictionary o is reset to an empty dictionary for the next iteration.
Once you run this code you will get this response.
Saving the data to a CSV file
For better visibility of this data, we are going to save this data to a CSV file. For this task, we are going to use the pandas library.
df = pd.DataFrame(l)
df.to_csv('properties.csv', index=False, encoding='utf-8')
The code uses the pandas library to create a DataFrame (df) from the list of dictionaries (l) that contains the scraped data. After creating the DataFrame, it is then exporting the DataFrame to a CSV file named 'properties.csv'.
After running the code you will find a CSV file inside your working folder by the name properties.csv.
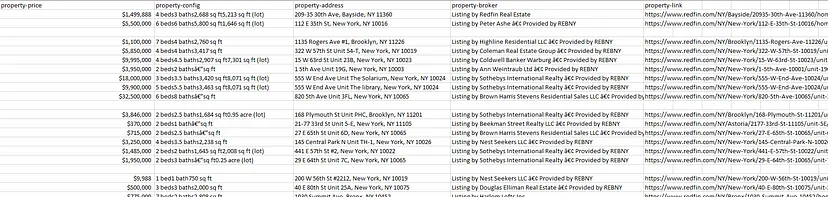
Saving the data from a list to a CSV file was super simple with Pandas.
Complete Code
You can scrape many more details from the page but for now, the code will look like this.
import requests
from bs4 import BeautifulSoup
import pandas as pd
l=[]
o={}
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
target_url="https://www.redfin.com/city/30749/NY/New-York/filter/status=active"
resp = requests.get(target_url,headers=head,verify=False)
print(resp.status_code)
soup=BeautifulSoup(resp.text,'html.parser')
allBoxes = soup.find_all("div",{"class":"HomeCardContainer"})
for box in allBoxes:
try:
o["property-price"]=box.find("span",{"class":"homecardV2Price"}).text.strip()
except:
o["property-price"]=None
try:
o["property-config"]=box.find("div",{"class":"HomeStatsV2"}).text.strip()
except:
o["property-config"]=None
try:
o["property-address"]=box.find("div",{"class":"homeAddressV2"}).text.strip()
except:
o["property-address"]=None
try:
o["property-broker"]=box.find("div",{"class":"brokerageDisclaimerV2"}).text.strip()
except:
o["property-broker"]=None
try:
o["property-link"]="https://www.redfin.com"+box.find("a").get('href')
except:
o["property-link"]=None
l.append(o)
o={}
print(l)
df = pd.DataFrame(l)
df.to_csv('properties.csv', index=False, encoding='utf-8')
Scraping Redfin Property Page
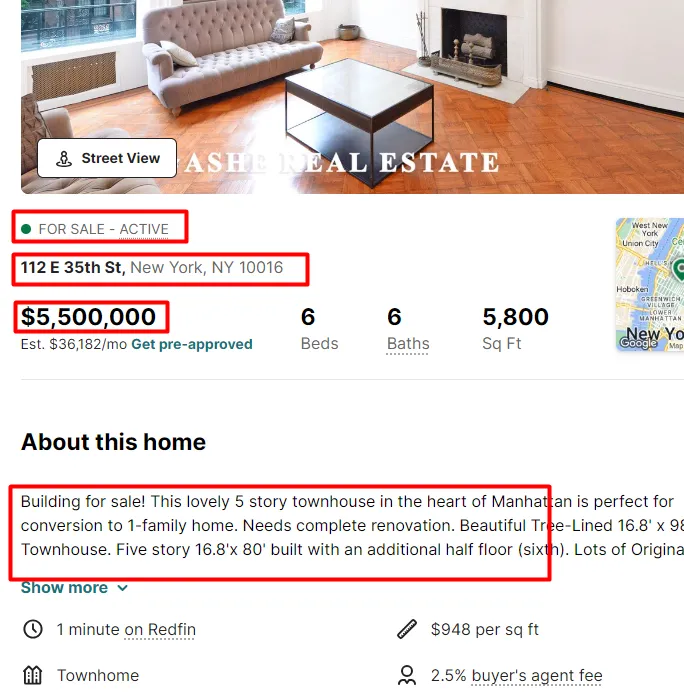
From the property page, we are going to gather this information.
- Property Price
- Property Address
- Is it still available(True/False)
- About section of the property
Download Raw HTML from the Page
import requests
from bs4 import BeautifulSoup
l=[]
o={}
available=False
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
target_url="https://www.redfin.com/NY/New-York/112-E-35th-St-10016/home/45333496"
resp = requests.get(target_url,headers=head,verify=False)
print(resp.status_code)
This Python code performs web scraping on a Redfin property page using the requests library to make an HTTP GET request and the BeautifulSoup library to parse the HTML content. The script initializes empty data structures (l and o) to store scraped information and sets a User-Agent header to simulate a Chrome browser request. The target URL is specified, and an HTTP GET request is sent with SSL certificate verification disabled.
After running the code if you get 200 on your console then that means your code was able to scrape the raw HTML from the target web page.
Let’s use BS4 to parse the data.
Parsing the Raw HTML
As usual, we have to first find the location of each element inside the DOM.
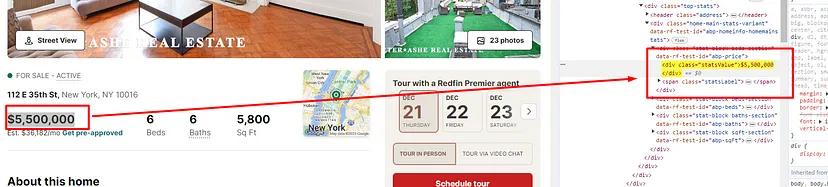
Price is stored inside the div tag with class statsValue.
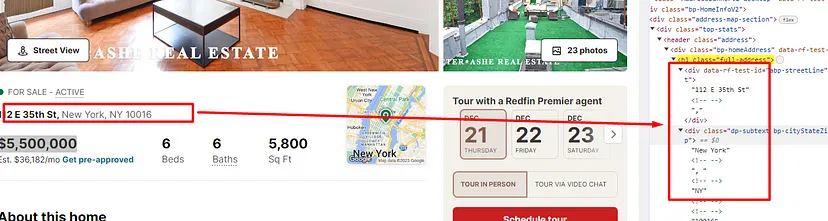
The address is stored inside the h1 tag with the class full-address.
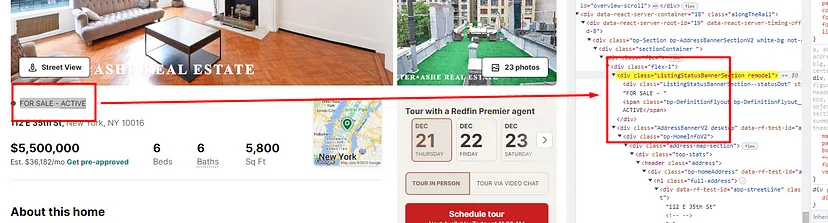
Property sale status is located inside the div tag with the class ListingStatusBannerSection.
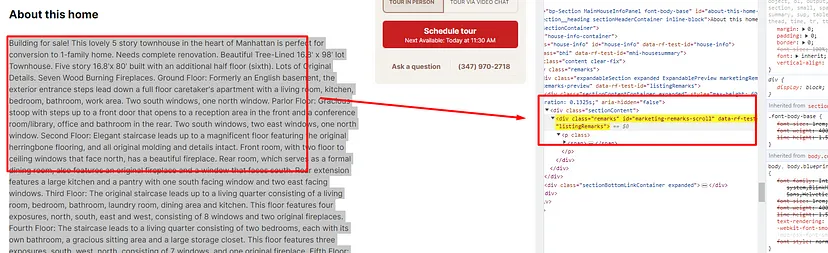
About section of the property can be found inside the div tag with id marketing-remarks-scroll.
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["property-price"]=soup.find("div",{"class":"statsValue"}).text.strip()
except:
o["property-price"]=None
try:
o["property-address"]=soup.find("h1",{"class":"full-address"}).text.strip()
except:
o["property-address"]=None
check = soup.find("div",{"class":"ListingStatusBannerSection"}).text.strip()
if "ACTIVE" in check:
available=True
else:
available=False
try:
o["property-available"]=available
except:
o["property-available"]=False
try:
o["about-property"]=soup.find("div",{"id":"marketing-remarks-scroll"}).text.strip()
except:
o["about-property"]=None
print(l)
By default available is set to False and it is set to True if the string ACTIVE is present inside the check string. We have used strip() function to remove the unwanted spaces from the text value.
Once you run the code you should get this.

Finally, we were able to extract all the desired information from the target page.
Complete Code
The complete code for this property page will look like this.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
available=False
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
target_url="https://www.redfin.com/NY/New-York/112-E-35th-St-10016/home/45333496"
resp = requests.get(target_url,headers=head,verify=False)
print(resp.status_code)
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["property-price"]=soup.find("div",{"class":"statsValue"}).text.strip()
except:
o["property-price"]=None
try:
o["property-address"]=soup.find("h1",{"class":"full-address"}).text.strip()
except:
o["property-address"]=None
check = soup.find("div",{"class":"ListingStatusBannerSection"}).text.strip()
if "ACTIVE" in check:
available=True
else:
available=False
try:
o["property-available"]=available
except:
o["property-available"]=False
try:
o["about-property"]=soup.find("div",{"id":"marketing-remarks-scroll"}).text.strip()
except:
o["about-property"]=None
l.append(o)
print(l)
Bonus Section
While scrolling down on the product page you will find information regarding agents, down payment, calculator, etc. This information loads through an AJAX injection.
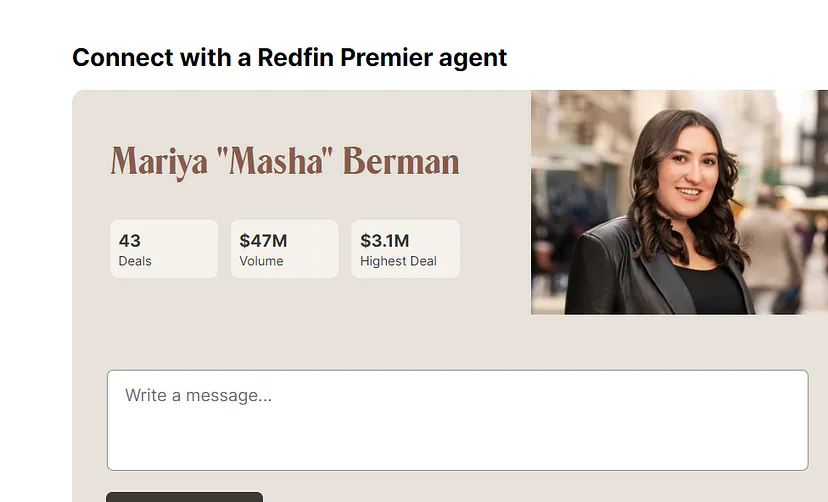
This cannot be scraped through a normal XHR request. At this point, many of you will think that this information can be scraped easily through a headless browser but the problem is that these headless browsers consume too much CPU resources. Well, let me share the alternate for this.
Redfin renders this data from the API calls it makes from the second last script tag of any property page. Let me explain to you what I mean over here.
The raw HTML you get after making the GET request will have a script tag in which all this data will be stored.
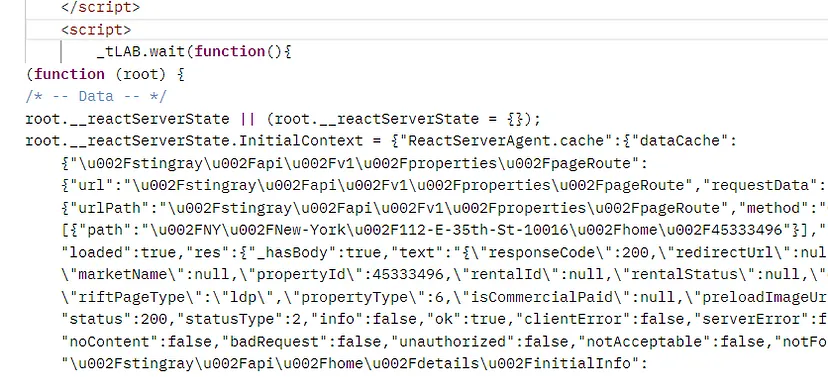
The script tag you see above is the second last script tag of the raw HTML downloaded from the target property page. Here is how using regular expression you can access the data from this tag.
try:
o["other-details"]=soup.find_all('script')[-2]
except:
o["other-details"]=None
config_match = re.search(r'reactServerState\.InitialContext\s*=\s*({.*?});', str(o["other-details"]))
if config_match:
config_data = config_match.group(1)
print(config_data)
Using regular expression we are finding a string that matches the pattern reactServerState\.InitialContext\s*=\s*({.*?});
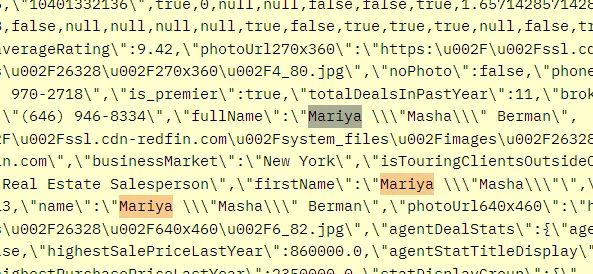
Once you run this code you will find all the information inside this string.
How to scrape Redfin at scale?
The above approach is fine until you are scraping a few hundred pages but this approach will fall flat when your scraping demands reach millions. Redfin will start throwing captcha pages like this.
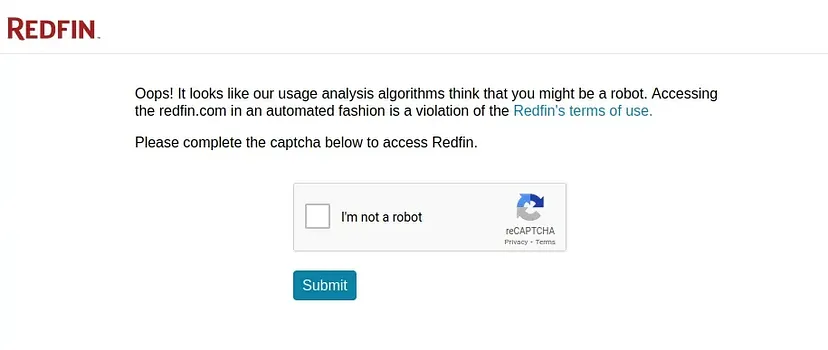
To avoid this situation you have to use a web scraping API like Scrapingdog. This API will handle proxy rotations for you. Proxy rotation will help you maintain the data pipeline.
You can sign up for the free account from here. The free account comes with a generous 1000 credits which is enough for testing the API.
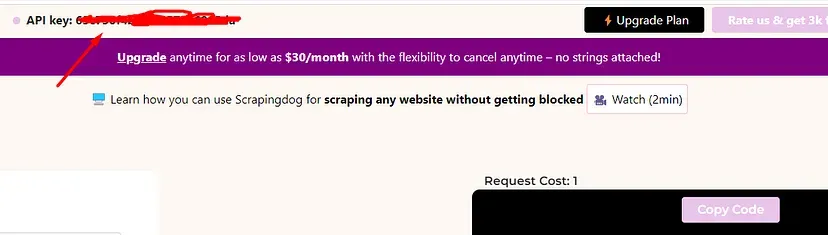
Once you are on the dashboard you will find an API key that will be used in the below code.
For this example, I am again using the Redfin search page.
import requests
from bs4 import BeautifulSoup
import pandas as pd
l=[]
o={}
target_url="https://api.scrapingdog.com/scrape?dynamic=false&api_key=YOUR-API-KEY&url=https://www.redfin.com/city/30749/NY/New-York/filter/status=active"
resp = requests.get(target_url)
print(resp.status_code)
soup=BeautifulSoup(resp.text,'html.parser')
allBoxes = soup.find_all("div",{"class":"HomeCardContainer"})
for box in allBoxes:
try:
o["property-price"]=box.find("span",{"class":"homecardV2Price"}).text.strip()
except:
o["property-price"]=None
try:
o["property-config"]=box.find("div",{"class":"HomeStatsV2"}).text.strip()
except:
o["property-config"]=None
try:
o["property-address"]=box.find("div",{"class":"homeAddressV2"}).text.strip()
except:
o["property-address"]=None
try:
o["property-broker"]=box.find("div",{"class":"brokerageDisclaimerV2"}).text.strip()
except:
o["property-broker"]=None
try:
o["property-link"]="https://www.redfin.com"+box.find("a").get('href')
except:
o["property-link"]=None
l.append(o)
o={}
print(l)
df = pd.DataFrame(l)
df.to_csv('properties.csv', index=False, encoding='utf-8')
Did you notice something? The code is almost the same as above we just replaced the target URL with the Scrapingdog API URL. Of course, you have to use your personal API key above to run this program successfully.
It is a very economical solution for large-scale scraping. You just have to focus on data collection and the rest will be managed by Scrapingdog.
Conclusion
In this blog, I have scraped two distinct types of pages on Redfin: the search page and the property page. Moreover, I have included a bonus section that sheds light on extracting information that’s dynamically loaded through AJAX injections.
Just like Redfin, I have extracted data from other real estate giants. (find their links below)
- Scraping Zillow Real Estate Property Data using Python
- Scraping Idealista.com using Python
- Web Scraping Realtor Property Data using Python
If this article resonates with you and you appreciate the effort put into this research, please share it with someone who might be on the lookout for scalable real estate data extraction solutions from property sites.
In the future, I will be making more such articles. If you found this article helpful, please share it. Thanks for reading!



