Introduction
Large Language Models (LLMs) have revolutionized the field of natural language processing, offering unprecedented capabilities in understanding and generating human-like text. One of the prominent platforms enabling the utilization of LLMs is Hugging Face. In this article, we’ll delve into the fascinating world of LLMs, exploring their significance and how Hugging Face plays a pivotal role in leveraging their potential.
Large Language Models (LLMs)
LLMs are advanced artificial intelligence models that have been trained on massive amounts of text data, enabling them to comprehend and generate human-like language. These models, such as GPT-3, have the ability to perform a wide range of language-related tasks, from answering questions and translating text to generating creative content.
Significance of LLMs
The significance of LLMs lies in their ability to process and understand contextual information within language. This makes them versatile tools for various applications, including natural language understanding, content creation, and even aiding in complex decision-making processes.
Hugging Face
Hugging Face is a platform that facilitates the use of LLMs, making them accessible to developers and researchers worldwide. With a user-friendly interface and a vast library of pre-trained models, Hugging Face simplifies the integration of LLMs into different applications, promoting innovation in natural language processing.
Data Summarization with LLMs
One notable application of LLMs is data summarization. Using Hugging Face, developers can harness the power of pre-trained models to automatically generate concise and coherent summaries of large datasets or documents. This streamlines the process of extracting key information, saving time and effort in information analysis.
How to Use Hugging Face for Data Summarization
- Select a Pre-trained Model: Hugging Face offers a variety of pre-trained LLMs. Choose a model that aligns with the nature of your data and summarization requirements.
- Install the Transformers Library: Hugging Face provides the Transformers library, a powerful tool for working with LLMs. Install it to easily incorporate pre-trained models into your code.
- Fine-tuning for Specific Needs: Depending on your specific use case, consider fine-tuning the pre-trained model on a dataset that reflects the nuances of your domain. This step ensures the model’s adaptability to your unique requirements.
- Generate Summaries: Utilize the fine-tuned model to generate summaries for your datasets. The output will be concise, coherent summaries that capture the essential information within the text.
Key Concepts in NLP
- Transformer: A type of neural network architecture introduced in the “Attention is All You Need” paper, known for its ability to capture contextual information efficiently, making it a cornerstone in natural language processing and various other tasks.
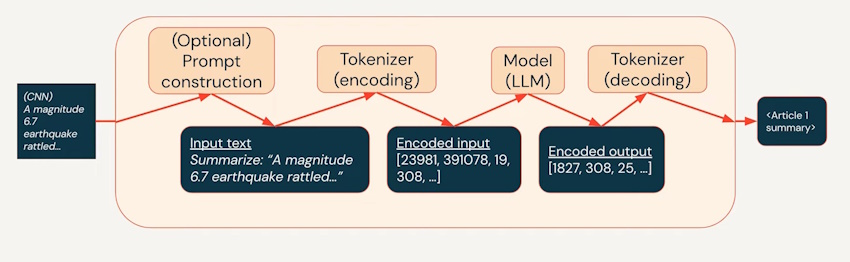
- Tokenizer: A tool that breaks down input text into smaller units, such as words or subwords, to facilitate language model processing; used to convert raw text into a format suitable for neural networks.
- Token ID: A numerical identifier assigned to each token in a tokenized sequence; helps represent words or subwords as discrete values in a format understandable by machine learning models.
- Encoding: The process of converting raw text or data into a numerical format, such as token IDs, to be fed into a machine learning model like a transformer.
- Decoding: The reverse process of encoding; converting numerical representations, such as token IDs, back into human-readable text; commonly used to interpret model-generated outputs like summaries or translations.
- Model: A trained neural network, such as a transformer-based model like T5, is designed to understand, generate, or summarize text based on learned patterns and parameters.
Code Snippet for Data Summarization in Databricks
Now we will implement the above concept practically in a databricks environment. Find the below codes and their respective explanations.
%pip install transformers
The %pip install transformers command is a magic command used in Jupyter notebooks or IPython environments. This command allows you to install Python packages directly within a notebook cell.
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Load pre-trained T5 model and tokenizer
model_name = "t5-small"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
# Sample content to be summarized
content = """
Title: The Impact of Artificial Intelligence on Society
Artificial Intelligence (AI) is transforming various aspects of our society, ranging from healthcare and finance to education and entertainment. As machine learning algorithms continue to advance, the impact of AI is becoming more profound.
In the healthcare sector, AI is being utilized for diagnosing diseases, predicting patient outcomes, and even developing new drugs. This has led to more personalized and effective healthcare solutions. Financial institutions leverage AI for fraud detection, risk assessment, and algorithmic trading, optimizing their operations and minimizing risks.
In education, AI is revolutionizing the learning experience with adaptive learning platforms and intelligent tutoring systems. These systems can tailor educational content to individual students' needs, enhancing the overall learning process. Additionally, AI is making its mark in the entertainment industry through recommendation algorithms, content creation, and virtual reality experiences.
While the benefits of AI are substantial, there are also concerns about ethical considerations and job displacement. The ethical use of AI, data privacy, and bias in algorithms are critical issues that need careful attention. Moreover, the automation of certain tasks raises questions about the future of work and the need for reskilling the workforce.
In conclusion, the impact of artificial intelligence on society is multifaceted. It brings about significant advancements and improvements in various sectors, but it also poses challenges that require thoughtful consideration. As we continue to integrate AI into our daily lives, it is crucial to strike a balance that ensures the responsible and ethical use of this powerful technology.
"""This first line of the code imports the necessary classes from the Hugging Face Transformers library, specifically the T5Tokenizer for tokenization and T5ForConditionalGeneration for loading the pre-trained T5 model.
Then we are instantiating the T5 tokenizer and model. The model is loaded with pre-trained weights, specifically the “t5-small” variant. This pre-trained model can be fine-tuned for various text generation tasks, including summarization.
Then we are passing the sample content that you want to summarize using the pre-trained T5 model.
# Tokenize and encode the content
inputs = tokenizer.encode("summarize: " + content, return_tensors="pt", max_length=512, truncation=True)
print(inputs)- tokenizer.encode: This method is used to tokenize and encode a given text. In this case, the text is “summarize: ” + content. The prefix “summarize: ” is added to instruct the T5 model to generate a summary of the provided content.
- return_tensors=”pt”: This parameter specifies that the output should be in PyTorch tensor format. The encoded sequence is converted into a PyTorch tensor, making it suitable for input to a PyTorch-based model like T5.
- max_length=512: This parameter sets the maximum length of the encoded sequence. If the content is longer than this maximum length after tokenization, it will be truncated to fit.
- truncation=True: This parameter indicates that truncation should be applied if the content exceeds the specified maximum length.
After running this code, the variable inputs will contain the tokenized and encoded representation of the input content, ready to be fed into the T5 model for summarization. Find the content of the input variable below.
tensor([[21603, 10, 11029, 10, 37, 14906, 13, 24714, 5869, 2825,
1433, 30, 3467, 24714, 5869, 2825, 1433, 41, 9822, 61,
19, 3, 21139, 796, 3149, 13, 69, 2710, 6, 3,
6836, 45, 4640, 11, 4747, 12, 1073, 11, 4527, 5,
282, 1437, 1036, 16783, 916, 12, 3245, 6, 8, 1113,
13, 7833, 19, 2852, 72, 13343, 5, 86, 8, 4640,
2393, 6, 7833, 19, 271, 11411, 21, 28252, 53, 6716,
6, 3, 29856, 1868, 6353, 6, 11, 237, 2421, 126,
4845, 5, 100, 65, 2237, 12, 72, 9354, 11, 1231,
4640, 1275, 5, 5421, 4222, 11531, 7833, 21, 7712, 10664,
6, 1020, 4193, 6, 11, 12628, 447, 3415, 6, 19769,
53, 70, 2673, 11, 3, 28807, 5217, 5, 86, 1073,
6, 7833, 19, 9481, 2610, 8, 1036, 351, 28, 25326,
1036, 5357, 11, 7951, 11179, 53, 1002, 5, 506, 1002,
54, 13766, 3472, 738, 12, 928, 481, 31, 523, 6,
3, 14762, 8, 1879, 1036, 433, 5, 5433, 6, 7833,
19, 492, 165, 3946, 16, 8, 4527, 681, 190, 10919,
16783, 6, 738, 3409, 6, 11, 4291, 2669, 2704, 5,
818, 8, 1393, 13, 7833, 33, 7354, 6, 132, 33,
92, 3315, 81, 11398, 4587, 7, 11, 613, 27780, 5,
37, 11398, 169, 13, 7833, 6, 331, 4570, 6, 11,
14387, 16, 16783, 33, 2404, 807, 24, 174, 6195, 1388,
5, 3, 7371, 6, 8, 11747, 13, 824, 4145, 3033,
7, 746, 81, 8, 647, 13, 161, 11, 8, 174,
21, 3, 60, 7, 10824, 53, 8, 10312, 5, 86,
7489, 6, 8, 1113, 13, 7353, 6123, 30, 2710, 19,
1249, 28842, 5, 94, 3200, 81, 1516, 14500, 7, 11,
6867, 16, 796, 8981, 6, 68, 34, 92, 15968, 2428,
24, 1457, 15908, 4587, 5, 282, 62, 916, 12, 9162,
7833, 139, 69, 1444, 1342, 6, 34, 19, 4462, 12,
6585, 3, 9, 2109, 24, 766, 7, 8, 1966, 11,
11398, 169, 13, 48, 2021, 748, 5, 1]])# Generate summary using the T5 model
summary_ids = model.generate(inputs, max_length=150, min_length=50, length_penalty=2.0, num_beams=4, early_stopping=True)
print(summary_ids)- model.generate: This method is used to generate text based on the provided input. In this case, it takes the tokenized and encoded input (inputs) and generates a summary using the T5 model.
- max_length=150: This parameter sets the maximum length of the generated summary to 150 tokens. If the summary exceeds this length, it will be truncated.
- min_length=50: This parameter sets the minimum length of the generated summary to 50 tokens. This helps ensure that the summary is not too short.
- length_penalty=2.0: This parameter applies a penalty to the length of the generated text. A higher length penalty encourages the model to generate shorter output.
- num_beams=4: This parameter controls the number of beams to use during beam search. Beam search is a technique used to generate multiple possible sequences and then select the one with the highest probability.
- early_stopping=True: This parameter allows the generation process to stop once a certain condition is met, such as when the specified max_length is reached.
After running this code, the variable summary_ids will contain the token IDs representing the generated summary. This tensor can be converted back into human-readable text using the T5 tokenizer. Find the content of the summary_ids variable below.
tensor([[ 0, 7833, 19, 271, 261, 21, 28252, 53, 6716, 6,
3, 29856, 1868, 6353, 6, 11, 237, 2421, 126, 4845,
3, 5, 16, 1073, 6, 7833, 19, 9481, 2610, 8,
1036, 351, 28, 25326, 1036, 5357, 11, 7951, 11179, 53,
1002, 3, 5, 11398, 169, 13, 7833, 6, 331, 4570,
6, 11, 14387, 16, 16783, 33, 2404, 807, 24, 174,
6195, 1388, 3, 5, 1]])# Decode the summary tensor correctly
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(summary)
- tokenizer.decode: This method is used to convert a sequence of token IDs back into a string of text. In this case, it takes the summary_ids tensor (containing token IDs of the generated summary) and decodes it into a readable text summary.
- summary_ids[0]: Accessing the first element of the tensor, as it typically contains the generated summary.
- skip_special_tokens=True: This parameter instructs the tokenizer to skip any special tokens that might be present in the decoded text. Special tokens are often used for purposes such as indicating the beginning or end of a sequence.
- clean_up_tokenization_spaces=True: This parameter helps clean up any extra spaces in the tokenized and decoded text.
After running this code, the variable summary will contain the human-readable summary of the input content generated by the T5 model. The print(summary) statement then displays this summary in the output.
The below-quoted text is the summarized content created with the help of the Hugging Face T5-small model.
AI is being used for diagnosing diseases, predicting patient outcomes, and even developing new drugs. in education, AI is revolutionizing the learning experience with adaptive learning platforms and intelligent tutoring systems. ethical use of AI, data privacy, and bias in algorithms are critical issues that need careful attention.
Conclusion
We’ve covered some important ideas in language tech and summarization. We explored how things like the Transformer, tokenization, and models like T5 make a big difference. These ideas are like building blocks that help us understand and use language technology better. Summarization, in particular, is a standout use of these tools. Our demo in Databricks showed that these ideas aren’t just for theory, they work in real-world situations too. We saw how these concepts can be smoothly used in platforms like Databricks to efficiently summarize data and pull out information. As AI keeps growing, these basics stay super important for making language models do cool stuff in all kinds of areas.
 and Its Revolutionary Potential | by Sidharth Sasikumar | May, 2024")



