Machine learning is a subfield of artificial intelligence (AI) that focuses on the development of algorithms and statistical models that enable computers to perform tasks without being explicitly programmed. The primary goal of machine learning is to enable computers to learn and improve from experience.
There are three main types of machine learning:
Supervised Learning:
In supervised learning, the algorithm is trained on a labeled dataset, which means that the input data is paired with the corresponding correct output. The algorithm learns to map inputs to outputs, making predictions or classifications based on the patterns it identifies in the training data.
Unsupervised Learning:
Unsupervised learning deals with unlabeled data. The algorithm explores the data to find patterns, relationships, or structures without explicit guidance on what to look for. Clustering and dimensionality reduction are common tasks in unsupervised learning.
Reinforcement Learning:
Reinforcement learning involves an agent that learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or punishments based on its actions, and it adjusts its strategy to maximize cumulative rewards over time.
Machine learning is applied in various domains, such as natural language processing, image recognition, speech recognition, recommendation systems, autonomous vehicles, and more. Common algorithms used in machine learning include linear regression, decision trees, support vector machines, neural networks, and deep learning models.
Deep learning, a subset of machine learning, involves the use of neural networks with multiple layers (deep neural networks). This approach has been particularly successful in tasks such as image and speech recognition.
In this article, we will discuss the basics of machine learning with TensorflowJS.
It is an open-source library developed by Google that allows machine learning models, particularly those built with TensorFlow, to run in web browsers or on Node.js. It enables developers to bring machine learning capabilities directly to the browser and NodeJS environments, allowing for client-side inference and real-time interactions. In this guide, We will concentrate on NodeJS not the browser.
This article is an intergral part of 3 a phase publication and in the second part we will train a large real world recommendation model for ecommerce products using TensorflowJS and in the third part, we will further discuss how to host and consume machine learning models including those trained with other technologies like Python’s Tensorflow, PyTorch among others in a NodeJS API.
Terminologies Used in Machine Learning with TensorflowJS
Tensor:
A tensor is a multi-dimensional array, a fundamental data structure in TensorFlow.js. Tensors can be scalars (0D), vectors (1D), matrices (2D), or have higher dimensions. They are the building blocks for data representation in machine learning models.
Model:
In machine learning, a model is a representation of a system or a pattern learned from data. In TensorFlow.js, models can be created using various architectures, such as neural networks.
Neural Network:
A neural network is a computational model inspired by the human brain. It consists of layers of interconnected nodes (neurons) that process input data to produce an output. TensorFlow.js supports the implementation of neural networks for various machine learning tasks.
Layers:
In the context of neural networks, layers are the building blocks that organize and process data. TensorFlow.js provides a layer API for constructing neural network architectures.
Training:
Training is the process of adjusting the parameters of a machine learning model using labeled data to minimize the difference between predicted and actual outputs. TensorFlow.js facilitates the training of models using optimization algorithms.
Inference:
Inference is the process of using a trained model to make predictions on new, unseen data. TensorFlow.js allows for efficient inference in real-time within web browsers or Node.js environments.
Loss Function:
The loss function measures the difference between the predicted output and the actual target values during training. TensorFlow.js provides various loss functions that can be used for different types of machine learning problems.
Optimizer:
An optimizer is an algorithm used during the training phase to minimize the loss function by adjusting the model’s parameters. TensorFlow.js offers a variety of optimizers, including stochastic gradient descent (SGD) and Adam.
Epoch:
An epoch is one complete pass through the entire training dataset during the training phase. Training typically involves multiple epochs to improve the model’s performance.
Batch Size:
During training, data is processed in batches rather than the entire dataset at once. Batch size refers to the number of data samples used in each iteration of the training process. TensorFlow.js allows developers to set batch sizes when training models.
Validation Data:
A separate set of data used during training to evaluate the model’s performance. TensorFlow.js enables the use of validation data to monitor and prevent overfitting.
Regression:
Regression is a type of supervised learning where the goal is to predict a continuous numerical output. In TensorFlow.js, regression models can be created using neural networks or other algorithms, and the training process involves minimizing the difference between predicted and actual numerical values.
Classification:
Classification is another type of supervised learning where the goal is to categorize input data into predefined classes or labels. TensorFlow.js supports classification tasks, and neural networks are often used for this purpose.
Testing Data (Test Set):
Testing data, also known as a test set, is a separate portion of the dataset that is not used during the training phase. It is reserved for evaluating the model’s performance after training. TensorFlow.js allows developers to assess how well a model generalizes to new, unseen data using a test set.
Validation Data:
Validation data is a subset of the dataset used during training to evaluate the model’s performance and tune hyperparameters. It is distinct from testing data, which is reserved for final evaluation after training.
Overfitting:
Overfitting occurs when a machine learning model performs well on the training data but fails to generalize to new, unseen data. TensorFlow.js provides techniques, such as regularization and dropout, to help mitigate overfitting.
Underfitting:
Underfitting happens when a model is too simple to capture the underlying patterns in the data. It leads to poor performance on both the training and testing datasets. Adjusting the model’s complexity or using more advanced architectures in TensorFlow.js can help address underfitting.
Hyperparameters:
Hyperparameters are configuration settings that are not learned from the data but are set before the training process. Examples include learning rate, batch size, and the number of layers in a neural network. Tuning hyperparameters is an important aspect of optimizing model performance in TensorFlow.js.
Activation Function:
Activation functions introduce non-linearity to the neural network, allowing it to learn complex patterns. TensorFlow.js provides various activation functions, such as ReLU (Rectified Linear Unit), Sigmoid, and Tanh, that can be applied to the layers of a neural network.
Data Preprocessing:
Data preprocessing involves preparing and cleaning the data before feeding it into a machine learning model. TensorFlow.js provides tools for standardizing, normalizing, and transforming data to improve model performance.
Callback:
In TensorFlow.js, a callback is a function that is executed at specific points during the training process. Callbacks can be used to perform tasks like saving model checkpoints, adjusting learning rates, or logging training metrics.
Prerequisites
Before we embark on the journey of learning TensorflowJS basics, it’s essential to ensure that your development environment is properly configured. This section outlines the prerequisites that you need to have in place before further diving into article.
Node.js and npm:
Have Node.js and npm (Node Package Manager) installed on your system. These are essential for training our models in a NodeJS environment. You can download Node.js from the official website or use a version manager like nvm for better control over Node.js versions.
Text Editor or IDE:
Choose a text editor or integrated development environment (IDE) for writing your TypeScript/JavaScript code. Popular choices include Visual Studio Code, Atom, or any editor of your preference.
JavaScript Basics
You should have basic understanding of JavaScript programming language, especially its most common data structures, arrays and objects, and their methods.
Basic Knowledge of Algorithm Scripting
Additionally, you should have some basic knowledge of algorithm scripting with JavaScript and familiar with optimising algorithms to run efficiently with a justifiable time and space complexity.
Environment setup for Machine Learning with TensorflowJS in NodeJS
In this article, we will discuss the basics of TensorflowJS by training basic and beginner friendly machine learning models.
Create a new folder in your desired location and open it with your desired code editor, in my case, I called it: nodejs_with_tensorflowjs.
Initialise a new nodejs project with the following command:
npm init -y
Step 2: Install TensorflowJS
Install the tensorflowjs with the following command:
npm install @tensorflow/tfjs
All set, create a new file: src/index.js in the root directory.
Before we start training our first AI model, lets first further discuss one of the previously discussed terminologies as its the basement for our first and second examples, by names of regression.
Like we ealier discussed, it is a type of supervised machine learning task where the goal is to predict a continuous numerical output based on input features. In other words, regression models are designed to establish a relationship between the input variables and a continuous target variable. The predicted output is a real-valued quantity, and the model aims to capture the underlying patterns in the data to make accurate predictions.
Key Concepts Related to Regression in ML with TensorflowJS:
Target Variable (Dependent Variable):
The variable that the model aims to predict. In regression, the target variable is continuous and numerical.
Features (Independent Variables):
The input variables or features that are used to make predictions for the target variable. These can be one or more variables that contribute to the prediction.
Linear Regression:
Linear regression is a common regression technique where the relationship between the input features and the target variable is modeled as a linear equation. The goal is to find the best-fitting line that minimizes the difference between the predicted values and the actual values.
Multiple Linear Regression:
In multiple linear regression, there are multiple independent variables influencing the target variable. The relationship is modeled as a linear combination of these variables.
Polynomial Regression:
Polynomial regression extends linear regression by allowing the relationship between variables to be modeled as a polynomial. This is useful when the underlying relationship is not linear.
Mean Squared Error (MSE):
MSE is a common metric used to evaluate the performance of regression models. It measures the average squared difference between the predicted values and the actual values. The goal during training is to minimize the MSE.
Training and Testing Data:
The dataset is typically divided into training and testing sets. The model is trained on the training set, and its performance is evaluated on the testing set to assess how well it generalizes to new, unseen data.
Residuals:
Residuals are the differences between the predicted values and the actual values in the testing set. Analyzing residuals helps in understanding how well the model captures the patterns in the data.
Coefficient and Intercept:
In linear regression, the coefficients represent the weights assigned to each feature, indicating their impact on the target variable. The intercept is the y-intercept of the regression line.
Regularization (L1 and L2):
Regularization techniques, such as L1 (Lasso) and L2 (Ridge), can be applied to regression models to prevent overfitting. They add penalty terms to the loss function, discouraging overly complex models.
Linear Regression Example
Scenario:
Imagine you have data points representing the number of hours students spend studying (x) and their corresponding exam scores (y).
Objective:
Build a model that can predict the exam score (y) based on the number of hours studied (x).
Model:
A simple linear regression model assumes that the relationship between hours studied and exam score is linear. It tries to fit a line to the data.
Equation:
The linear regression equation is typically represented as y = mx + b, where m is the slope of the line, and b is the y-intercept.
Training:
During training, the model adjusts the values of m and b to best fit the training data.
Prediction:
Once trained, the model can predict the exam score for a given number of hours studied.
Now that we have a basic understanding of linear regression, lets have our scenario practical by training the described model.
In the created file: src/index.js, place the following code:
const tf = require("@tensorflow/tfjs");
// Define your model and training logic here
const model = tf.sequential();
model.add(tf.layers.dense({ units: 1, inputShape: [1] }));
model.compile({ optimizer: "sgd", loss: "meanSquaredError" });
// Example data
const xs = tf.tensor2d([1, 2, 3, 4], [4, 1]); // Features (hours of study)
const ys = tf.tensor2d([2, 4, 6, 8], [4, 1]); // Labels (exam scores)
// Train the model
model.fit(xs, ys, { epochs: 100 }).then(() => {
// Model is trained
model.predict(tf.tensor2d([5], [1, 1])).print();
});
Explanation
We have data representing the number of hours students spend studying (x) and their corresponding exam scores (y).
The input data, often referred to as features (x), represents the independent variable, in this case, the number of hours students spend studying.
const xs = tf.tensor2d([1, 2, 3, 4], [4, 1]);
The xs tensor represents a 2D array with 4 rows (samples) and 1 column. Each row corresponds to a different student, and the column contains the number of hours that student spent studying.
1 hour for the first student
2 hours for the second student
3 hours for the third student
4 hours for the fourth student
On the other hand, the output data, often referred to as labels (y), represents the dependent variable, in this case, the exam scores corresponding to the hours of study.
const ys = tf.tensor2d([2, 4, 6, 8], [4, 1]);
The ys tensor represents a 2D array with 4 rows (samples) and 1 column. Each row corresponds to a different student, and the column contains the corresponding exam score.
Exam score 2 for the first student (who studied 1 hour)
Exam score 4 for the second student (who studied 2 hours)
Exam score 6 for the third student (who studied 3 hours)
Exam score 8 for the fourth student (who studied 4 hours)
Relationship and Objective:
The goal of our linear regression model is to learn the relationship between the number of hours studied (x) and the corresponding exam scores (y).
During training, the model adjusts its parameters (slope and y-intercept of the line) to minimize the difference between its predictions and the actual exam scores.
Once trained, the model can predict the exam score for a new student based on the number of hours that student spent studying.
Linear Regression Equation:
In the context of linear regression, the relationship is often represented by the equation y = mx + b, where:
y is the predicted output (exam score),
x is the input feature (hours of study),
m is the slope of the line, and
b is the y-intercept.
The model’s goal during training is to find the values of m and b that best fit the training data.
Training and Prediction:
During training, the model adjusts m and b to minimize the difference (error) between its predictions and the actual exam scores.
After training, the model can make predictions for new students. For example, given a new student who studied 5 hours:
const testInput = tf.tensor2d([5], [1, 1]);
const prediction = model.predict(testInput);
prediction.print();
The output of this prediction would be the model’s estimate of the exam score for a student who studied 5 hours.
Lets now run our code:
Add the following script to the scripts section in your package.json:
"start": "node src/index.js"
On the terminal, run:
npm start
You should see the following in terminal:
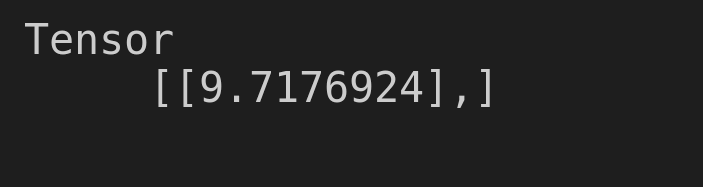
Indicating that our model predicted the value: 9.7176924 to be the exam score for our test student who studied for 5 hours. Value is close to 10 so our model has surely tried since from our test data, the exam score was always double the hours studied.
Note that the larger the training data, the more accurate the model and the longer the training duration.
Example 2: Linear Regression for House Prices
Imagine a dataset with three features: size of the house, number of bedrooms, and distance to the city center.
We’ll generate a larger synthetic dataset using random values and train a model for predicting house prices basing on the 3 features.
In the previous example, we used @tensorflow.js/tfjs, however, this library uses pure JavaScript implementations for operations, running on the CPU and is slower due to JavaScript-based execution. However, it runs both in web browsers and Node.js environments.
Since our concentration in this article is NodeJS, we will use a faster TensorflowJS library optimized to run only in NodeJS environments by names of @tensorflow/tfjs-node .
It leverages native TensorFlow C++ bindings for faster execution and is significantly faster than @tensorflow/tfjs due to native code execution and can utilize GPU acceleration with CUDA (or Compute Unified Device Architecture), a proprietary and closed-source parallel computing platform and application programming interface (API) that allows software to use certain types of graphics processing units (GPUs) for general-purpose processing), (if available).
Note that,if youre into high-performance ML tasks in Node.js, its recommended you use @tensorflow/tfjs-node-gpu as it is significantly faster (with GPU) compared to both @tensorflow/tfjs-node and @tensorflow/tfjs, and provides exceptional GPU support.
However, it requires NVIDIA GPU with CUDA, is not officially supported on macOS and also has many experimental features on windows OS despite the fact that its already stable on Linux OS.
In this guide, we will be proceeding with @tensorflow/tfjs-node
On the terminal,run the following command:
npm install @tensorflow/tfjs-node
Create a new file: src/train.js and place the following code:
const tf = require("@tensorflow/tfjs-node");
// Generate a synthetic dataset
const generateDataset = (numSamples) => {
const sizes = Array.from(
{ length: numSamples },
() => Math.random() * 3000 + 500
);
const bedrooms = Array.from(
{ length: numSamples },
() => Math.floor(Math.random() * 5) + 1
);
const distances = Array.from(
{ length: numSamples },
() => Math.random() * 20
);
const prices = sizes.map(
(size, i) =>
1000 * size +
20000 * bedrooms[i] -
1000 * distances[i] +
Math.random() * 10000
);
return { sizes, bedrooms, distances, prices };
};
const numSamples = 1000;
const { sizes, bedrooms, distances, prices } = generateDataset(numSamples);
// Store the generated dataset for inspection
const datasetForInspection = { sizes, bedrooms, distances, prices };
// Create tensors from the data
const xs = tf
.tensor2d([sizes, bedrooms, distances], [3, numSamples])
.transpose();
const ys = tf.tensor2d(prices, [numSamples, 1]);
// Model architecture
const model = tf.sequential();
model.add(tf.layers.dense({ units: 64, inputShape: [3], activation: "relu" }));
model.add(tf.layers.dense({ units: 1 }));
model.compile({ optimizer: "adam", loss: "meanSquaredError" });
// Training
model.fit(xs, ys, { epochs: 50 }).then(() => {
// Model is trained
// You can use the trained model to make predictions
const newHouseFeatures = tf.tensor2d([[1500, 3, 10]]);
const prediction = model.predict(newHouseFeatures);
console.log("Predicted Price:", prediction.dataSync()[0]);
});
Explanation
Before we run our code,lets first understand it line by line:
Step 1: Import TensorFlow.js:
const tf = require('@tensorflow/tfjs-node');
Step 2: Generate Synthetic Dataset:
Define a function generateDataset to create a synthetic dataset with random values for sizes, bedrooms, distances, and corresponding prices.
Generate a dataset with 1000 samples and store it in variables.
const generateDataset = (numSamples) => {
// ... (Randomly generate sizes, bedrooms, distances, and prices)
};
const numSamples = 1000;
const { sizes, bedrooms, distances, prices } = generateDataset(numSamples);
This dataset will be replaced with actual training data and is randomly generated for now since we donot have a prepared dataset for training our model.
Step 3: Store Dataset for Inspection:
Store the generated dataset in a variable for inspection. You can log this variable to see the generated data.
const datasetForInspection = { sizes, bedrooms, distances, prices };
Step 4: Create Tensors from Data
const xs = tf.tensor2d([sizes, bedrooms, distances], [3, numSamples]).transpose();
const ys = tf.tensor2d(prices, [numSamples, 1]);
Create TensorFlow tensors from the features (xs) and labels (ys). The transpose() is used to reshape the data.
Creating Input Tensor (xs):
tf.tensor2d: This creates a 2D tensor. The first argument is an array containing the data, and the second argument is the shape of the tensor.
The input data for the features (sizes, bedrooms, distances) is provided as an array [sizes, bedrooms, distances].
The shape of the tensor is specified as [3, numSamples] because there are three features (size, bedrooms, distances) for each of the numSamples houses..transpose(): This transposes the tensor, swapping its dimensions. The original shape was [3, numSamples], and after transposing, it becomes [numSamples, 3]. This is a very common step to make the data compatible with the model’s input shape.
Creating Output Tensor (ys):
tf.tensor2d: Similar to the input tensor creation, this creates a 2D tensor for the output (prices).
The first argument is an array containing the output data (prices).
The shape of the tensor is [numSamples, 1], indicating that there is one output value (price) for each of the numSamples houses.
Step 5: Model Architecture:
const model = tf.sequential();
model.add(tf.layers.dense({ units: 64, inputShape: [3], activation: 'relu' }));
model.add(tf.layers.dense({ units: 1 }));
We define a sequential model with two dense layers. The first layer has 64 units and uses the ReLU activation function. The second layer has 1 unit.
Step 6: Compile the Model
model.compile({ optimizer: 'adam', loss: 'meanSquaredError' });
Compile the model with the Adam optimizer and mean squared error loss function
Step 7: Use Trained Model to Make Prediction
Once the model is trained, you can use it to make predictions. For example, predict the price for a new house with features [1500, 3, 10]:
model.fit(xs, ys, { epochs: 50 }).then(() => {
// Model is trained
// You can use the trained model to make predictions
const newHouseFeatures = tf.tensor2d([[1500, 3, 10]]);
const prediction = model.predict(newHouseFeatures);
console.log('Predicted Price:', prediction.dataSync()[0]);
});
This code creates a tensor for new house features, passes it to the trained model, and logs the predicted price.
In the terminal, run:
npm start
and you should have a terminal with the following ending:
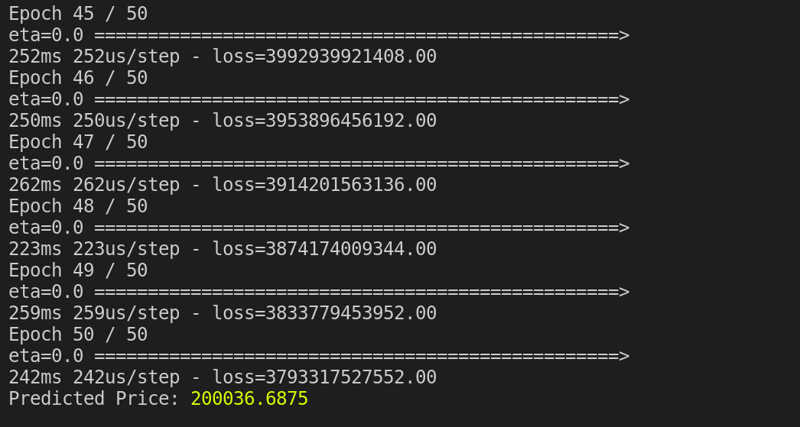
Indicating that, our model predicts 200036.6875 to be the price for a new house with features [1500, 3, 10].
Time Complexity of generateDataset() Function
The time complexity of the generateDataset function, which creates a synthetic dataset with random values for sizes, bedrooms, distances, and prices, is primarily determined by the number of samples (numSamples). Let’s analyze the time complexity:
const generateDataset = (numSamples) => {
const sizes = Array.from({ length: numSamples }, () => Math.random() * 3000 + 500);
const bedrooms = Array.from({ length: numSamples }, () => Math.floor(Math.random() * 5) + 1);
const distances = Array.from({ length: numSamples }, () => Math.random() * 20);
const prices = sizes.map((size, i) => 1000 * size + 20000 * bedrooms[i] - 1000 * distances[i] + Math.random() * 10000);
return { sizes, bedrooms, distances, prices };
};
Generating Random Values:
The sizes, bedrooms, and distances arrays are generated using Array.from() with a length of numSamples.
The time complexity for each of these arrays is O(numSamples).
Generating Prices:
The prices array is generated using the map function. The time complexity of the map function is O(numSamples).
Inside the map function, each element is calculated using basic arithmetic operations, which are constant time operations.
The overall time complexity of the generateDataset function is dominated by the generation of sizes, bedrooms, and distances, making it O(numSamples), more clearly, 0(n) that is linear time complexity.
Pretty good, but keep in mind that our analysis assumes that basic arithmetic operations are considered constant time, which is a reasonable assumption for typical use cases. If you have a specific requirement for precision or if you are dealing with extremely large datasets, further considerations may be necessary. Additionally, the random number generation itself may have a time complexity that depends on the specific implementation of the random number generator.
Possibly, the time complexity can be linearly proportional to the number of samples (numSamples). If you have a large dataset, the generation time will scale linearly with the size of the dataset.
Training ML Model on Text Data (Sentiment Analysis Example)
Our previous 2 examples have all been using a dataset with numeric data, however, at times, you will have text data or a mix of both to train your AI model. Lets take a last example using text based data.
We’ll build a simple model to classify text into two categories: positive and negative. This is often referred to as sentiment analysis. However, in our example, tone of the message/text will either be positive or negative.
Often in sentiment analysis, digital text is analyzed to determine if the emotional tone of the message is positive, negative, or neutral.
Create a new file: src/textdata.js and place the following code:
const tf = require("@tensorflow/tfjs-node");
// Given data
const textData = ["good", "bad", "happy", "sad", "positive", "negative"];
const labels = [1, 0, 1, 0, 1, 0]; // 1: Positive, 0: Negative
// Preprocess data
const tokenize = (text) => text.toLowerCase().split(" ");
const maxSeqLength = textData.reduce(
(max, text) => Math.max(max, tokenize(text).length),
0
);
const padSequence = (sequence, maxLength) => {
return Array.from({ length: maxLength - sequence.length }, () => 0).concat(
sequence
);
};
const xData = textData.map((text) => {
const tokens = tokenize(text);
const sequence = tokens.map(
(token) => token.charCodeAt(0) - "a".charCodeAt(0) + 1
); // Simple character encoding
return padSequence(sequence, maxSeqLength);
});
const yData = tf.tensor1d(labels);
// Define the model
const model = tf.sequential();
model.add(
tf.layers.embedding({ inputDim: 27, outputDim: 8, inputLength: maxSeqLength })
);
model.add(tf.layers.flatten());
model.add(tf.layers.dense({ units: 1, activation: "sigmoid" }));
model.compile({
optimizer: tf.train.adam(),
loss: "binaryCrossentropy",
metrics: ["accuracy"],
});
// Convert data to tensors
const xTrain = tf.tensor2d(xData);
const yTrain = yData;
// Train the model
model.fit(xTrain, yTrain, { epochs: 100 }).then((history) => {
console.log("Training complete.");
// Test the model with custom data
const customTestData = ["awesome", "terrible", "excited", "disappointed"];
const xCustomTestData = customTestData.map((text) => {
const tokens = tokenize(text);
const sequence = tokens.map(
(token) => token.charCodeAt(0) - "a".charCodeAt(0) + 1
);
return padSequence(sequence, maxSeqLength);
});
const xCustomTest = tf.tensor2d(xCustomTestData);
// Make predictions
const predictions = model.predict(xCustomTest);
const results = predictions.arraySync();
console.log("Custom Test Data Predictions:", results);
});
Explanation:
Import the TensorFlow.js Node.js bindings.
const tf = require("@tensorflow/tfjs-node")
Define an array of text data and corresponding labels indicating positive (1) or negative (0) sentiment.
const textData = ["good", "bad", "happy", "sad", "positive", "negative"];
const labels = [1, 0, 1, 0, 1, 0]; // 1: Positive, 0: Negative
Define a function (tokenize) to convert text to lowercase and split it into tokens. Determine the maximum sequence length in the dataset.
const tokenize = (text) => text.toLowerCase().split(" ");
const maxSeqLength = textData.reduce(
(max, text) => Math.max(max, tokenize(text).length),
0
);
Define a function (padSequence) to pad sequences with zeros to ensure uniform length.
const padSequence = (sequence, maxLength) => {
return Array.from({ length: maxLength - sequence.length }, () => 0).concat(
sequence
);
};
Convert text data to numerical sequences by mapping each text to a numerical sequence using a simple character encoding and pad the sequences to the maximum length.
const xData = textData.map((text) => {
const tokens = tokenize(text);
const sequence = tokens.map(
(token) => token.charCodeAt(0) - "a".charCodeAt(0) + 1
); // Simple character encoding
return padSequence(sequence, maxSeqLength);
});
Create labels tensor by converting the labels array into a TensorFlow tensor.
const yData = tf.tensor1d(labels);
Create a sequential model with an embedding layer, a flatten layer, and a dense layer with a sigmoid activation function.
const model = tf.sequential();
model.add(
tf.layers.embedding({ inputDim: 27, outputDim: 8, inputLength: maxSeqLength })
);
model.add(tf.layers.flatten());
model.add(tf.layers.dense({ units: 1, activation: "sigmoid" }));
Compile the model
Specify the optimizer, loss function, and metrics for model training.
model.compile({
optimizer: tf.train.adam(),
loss: "binaryCrossentropy",
metrics: ["accuracy"],
});
Convert input data (xData) and labels (yData) to TensorFlow tensors.
const xTrain = tf.tensor2d(xData);
const yTrain = yData;
Train the model using the training data (xTrain and yTrain) for 100 epochs.
model.fit(xTrain, yTrain, { epochs: 100 }).then((history) => {
console.log("Training complete.");
});
Test the model with custom data
Create sequences for custom test data, convert them to a tensor, make predictions using the trained model, and log the results.
const customTestData = ["awesome", "terrible", "excited", "disappointed"];
const xCustomTestData = customTestData.map((text) => {
const tokens = tokenize(text);
const sequence = tokens.map(
(token) => token.charCodeAt(0) - "a".charCodeAt(0) + 1
);
return padSequence(sequence, maxSeqLength);
});
const xCustomTest = tf.tensor2d(xCustomTestData);
const predictions = model.predict(xCustomTest);
const results = predictions.arraySync();
console.log("Custom Test Data Predictions:", results);
Update the index file to point to the our new file and run:
npm start
You should have the following terminal:
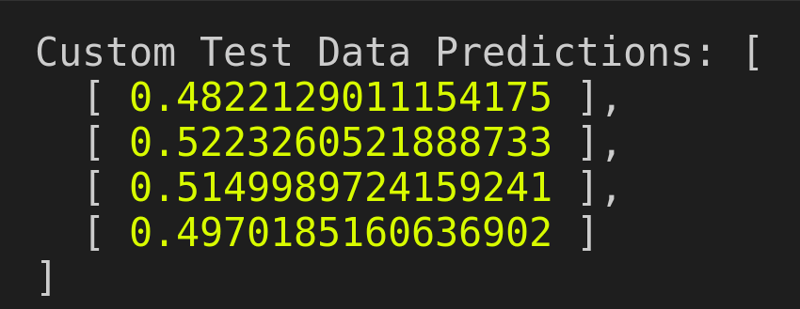
In a binary classification problem (such as sentiment analysis with positive/negative classes), a common threshold is 0.5. You can interpret the predictions by considering values above 0.5 as predicting positive sentiment and values below 0.5 as predicting negative sentiment. In our case, the model’s predictions are close to the threshold, indicating some uncertainty in the classification.
This is because our training data/dataset was too small for it to confidently predict.
Here is summary explanation:
[
0.4822129011154175,
0.5223260521888733,
0.5149989724159241,
0.4970185160636902
] === [“awesome”, “terrible”, “excited”, “disappointed”]
Given the little dataset we trained our model on,it has tried.
As earlier discussed, the larger the training data/dataset, the more accurate the model and the longer the training period.
Conclusion
In conclusion, we explored the fundamentals of machine learning using TensorFlowJS, showcasing its versatility through three distinct examples. We delved into the basics with two numerical datasets, demonstrating the process of training models to make predictions. Additionally, we ventured into the realm of natural language processing by employing TensorFlow.js to create a sentiment analysis model based on text data.
Through these examples, we’ve witnessed how TensorFlowJS empowers developers and data scientists to implement machine learning solutions across various domains. From numerical predictions to text-based sentiment analysis, TensorFlowJS’s flexibility and ease of use make it a powerful tool for anyone seeking to leverage machine learning in their NodeJS projects. As the field of machine learning continues to evolve, TensorFlowJS remains at the forefront, providing a robust framework for both beginners and seasoned practitioners to explore and implement cutting-edge solutions. Whether you’re working with numerical data or engaging in the complexities of natural language processing, TensorFlowJS stands as a reliable companion in the exciting journey of machine learning in NodeJS environments.
Until next time, happy coding!

 – Azure Aggregator")


