Author(s): Amit Chauhan
Originally published on Towards AI.
Segmentation algorithm based on machine learning approach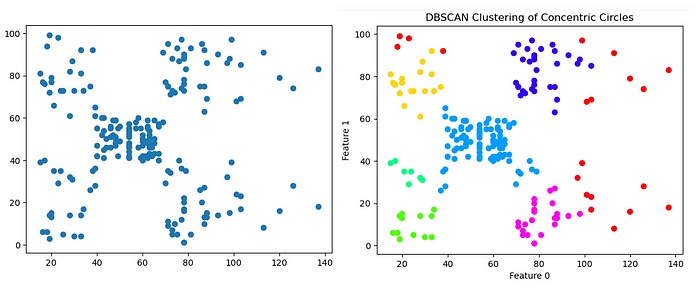
The output clusters of DBSCAN. An image by the Author
In this article, the DBSCAN algorithm creates clusters in more easier way than K-Means or Hierarchical clustering algorithms. This new clustering algorithm is well suited where the dataset contains some amount of noise data. Based on the density feature, it easily identifies the clusters and noise as outliers.
The full name of DBSCAN is Density Based Spatial Clustering of Application with Noise.
In K-means, we need the k value to create clusters with the help of the elbow method and choosing the number where variance shows no change on adding other clusters.
While Hierarchical clustering is based on distance metrics and linkage criteria. That determines the similarity between points and the requirement of merge or split, respectively.
Where we use DBSCAN:
If the data is irregular in shape or non-globular, remove outliers and well-suited proximity in spatial datasets. This method can be used for customer segmentation.
Why move from K-means clustering to new DBSCAN clustering?
There can be various reasons, the main reasons are shown below:
In k-means, we need to tell the number of clusters with the help of the elbow method. Sometimes the elbow curve shows ambiguity between cluster points.K-means is sensitive to the outlier, the centroid… Read the full blog for free on Medium.
Published via Towards AI




