- Slow build times and inefficiencies in packaging and distributing execution files were costing our ML/AI engineers a significant amount of time while working on our training stack.
- By addressing these issues head-on, we were able to reduce this overhead by double-digit percentages.
In the fast-paced world of AI/ML development, it’s crucial to ensure that our infrastructure can keep up with the increasing demands and needs of our ML engineers, whose workflows include checking out code, writing code, building, packaging, and verification.
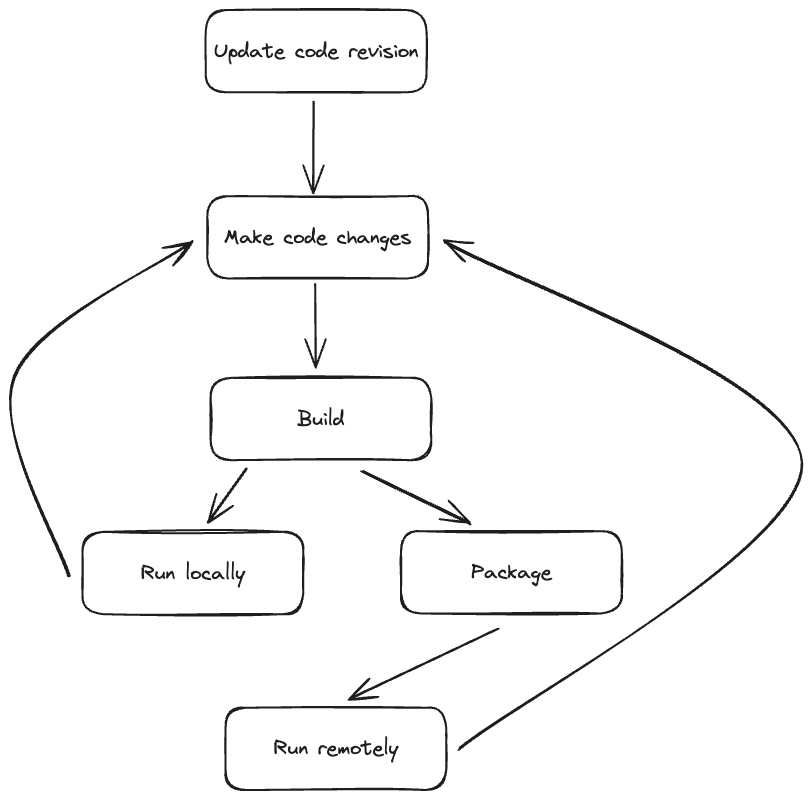
In our efforts to maintain efficiency and productivity while empowering our ML/AI engineers to deliver cutting-edge solutions, we found two major challenges that needed to be addressed head-on: slow builds and inefficiencies in packaging and distributing executable files.
The frustrating problem of slow builds often arises when ML engineers work on older (“cold”) revisions for which our build infrastructure doesn’t maintain a high cache hit rate, requiring us to repeatedly rebuild and relink many components. Moreover, build non-determinism further contributes to rebuilding by introducing inefficiencies and producing different outputs for the same source code, making previously cached results unusable.
Executable packaging and distribution was another significant challenge because, historically, most ML Python executables were represented as XAR files (self-contained executables) and it is not always possible to leverage OSS layer-based solutions efficiently (see more details below). Unfortunately, creating such executables can be computationally costly, especially when dealing with a large number of files or substantial file sizes. Even if a developer modifies only a few Python files, a full XAR file reassembly and distribution is often required, causing delays for the executable to be executed on remote machines.
Our goal in improving build speed was to minimize the need for extensive rebuilding. To accomplish this, we streamlined the build graph by reducing dependency counts, mitigated the challenges posed by build non-determinism, and maximized the utilization of built artifacts.
Simultaneously, our efforts in packaging and distribution aimed to introduce incrementality support, thereby eliminating the time-consuming overhead associated with XAR creation and distribution.
How we improved build speeds
To make builds faster we wanted to ensure that we built as little as possible by addressing non-determinism and eliminating unused code and dependencies.
We identified two sources of build non-determinism:
- Non-determinism in tooling. Some compilers, such as Clang, Rustc, and NVCC, can produce different binary files for the same input, leading to non-deterministic results. Tackling these tooling non-determinism issues proved challenging, as they often required extensive root cause analysis and time-consuming fixes.
- Non-determinism in source code and build rules. Developers, whether intentionally or unintentionally, introduced non-determinism by incorporating things like temporary directories, random values, or timestamps into build rules code. Addressing these issues posed a similar challenge, demanding a substantial investment of time to identify and fix.
Thanks to Buck2, which sends nearly all of the build actions to the Remote Execution (RE) service, we have been able to successfully implement non-determinism mitigation within RE. Now we provide consistent outputs for identical actions, paving the way for the adoption of a warm and stable revision for ML development. In practice, this approach will eliminate build times in many cases.
Though removing the build process from the critical path of ML engineers might not be possible in all cases, we understand how important it is to handle dependencies for controlling build times. As dependencies naturally increased, we made enhancements to our tools for managing them better. These improvements helped us find and remove many unnecessary dependencies, making build graph analysis and overall build times much better. For example, we removed GPU code from the final binary when it wasn’t needed and figured out ways to identify which Python modules are actually used and cut native code using linker maps.
Adding incrementality for executable distribution
A typical self-executable Python binary, when unarchived, is represented by thousands of Python files (.py and/or .pyc), substantial native libraries, and the Python interpreter. The cumulative result is a multitude of files, often numbering in the hundreds of thousands, with a total size reaching tens of gigabytes.
Engineers spend a significant amount of time dealing with incremental builds where packaging and fetching overhead of such a large executable surpasses the build time. In response to this challenge, we implemented a new solution for the packaging and distribution of Python executables – the Content Addressable Filesystem (CAF).
The primary strength of CAF lies in its ability to operate incrementally during content addressable file packaging and fetching stages:
- Packaging: By adopting a content-aware approach, CAF can intelligently skip redundant uploads of files already present in Content Addressable Storage (CAS), whether as part of a different executable or the same executable with a different version.
- Fetching: CAF maintains a cache on the destination host, ensuring that only content not already present in the cache needs to be downloaded.
To optimize the efficiency of this system, we deploy a CAS daemon on the majority of Meta’s data center hosts. The CAS daemon assumes multiple responsibilities, including maintaining the local cache on the host (materialization into the cache and cache GC) and organizing a P2P network with other CAS daemon instances using Owl, our high-fanout distribution system for large data objects. This P2P network enables direct content fetching from other CAS daemon instances, significantly reducing latency and storage bandwidth capacity.
In the case of CAF, an executable is defined by a flat manifest file detailing all symlinks, directories, hard links, and files, along with their digest and attributes. This manifest implementation allows us to deduplicate all unique files across executables and implement a smart affinity/routing mechanism for scheduling, thereby minimizing the amount of content that needs to be downloaded by maximizing local cache utilization.
While the concept may bear some resemblance to what Docker achieves with OverlayFS, our approach differs significantly. Organizing proper layers is not always feasible in our case due to the number of executables with diverse dependencies. In this context, layering becomes less efficient and its organization becomes more complex to achieve. Additionally direct access to files is essential for P2P support.
We opted for Btrfs as our filesystem because of its compression and ability to write compressed storage data directly to extents, which bypasses redundant decompression and compression and Copy-on-write (COW) capabilities. These attributes allow us to maintain executables on block devices with a total size similar to those represented as XAR files, share the same files from cache across executables, and implement a highly efficient COW mechanism that, when needed, only copies affected file extents.
LazyCAF and enforcing uniform revisions: Areas for further ML iteration improvements
The improvements we implemented have proven highly effective, drastically reducing the overhead and significantly elevating the efficiency of our ML engineers. Faster build times and more efficient packaging and distribution of executables have reduced overhead by double-digit percentages.
Yet, our journey to slash build overhead doesn’t end here. We’ve identified several promising improvements that we aim to deliver soon. In our investigation into our ML workflows, we discovered that only a fraction of the entire executable content is utilized in certain scenarios. Recognizing that, we intend to start working on optimizations to fetch executable parts on demand, thereby significantly reducing materialization time and minimizing the overall disk footprint.
We can also further accelerate the development process by enforcing uniform revisions. We plan to enable all our ML engineers to operate on the same revision, which will improve the cache hit ratios of our build. This move will further increase the percentage of incremental builds since most of the artifacts will be cached.
")




