Data is at the heart of the modern enterprise, helping organizations to better understand their customers, make better business decisions, improve business processes, track inventory, monitor competitors and take other steps to successfully run their operations. But over the past two decades, many organizations have had to get a better grasp on how to handle the increasing amounts and different forms of data — i.e., big data — that they’re now creating and collecting.
In many cases, big data is so large and complex, with a combination of structured, unstructured and semistructured data, that traditional data management technologies can’t process, store and manage it effectively or efficiently. With regular data warehouses not a good fit, Spark, Hadoop, NoSQL databases and other big data platforms and tools have emerged to help fill the gap and enable businesses to set up data lakes as repositories for all that data.
However, simply doing so isn’t sufficient to get business value from big data. Nor do conventional data analytics applications fully tap its potential benefits. As more companies master the big data management process, forward-thinking ones are applying intelligent and advanced forms of analytics to extract more value from the data in their systems. In particular, machine learning, which can spot patterns and provide cognitive capabilities across large volumes of data, gives organizations the ability to take their big data analytics initiatives to the next level.
How are big data and machine learning related?
Using machine learning algorithms for big data analytics is a logical step for companies looking to maximize their data’s potential value. Machine learning tools use data-driven algorithms and statistical models to analyze data sets and then draw inferences from identified patterns or make predictions based on them. The algorithms learn from the data as they run against it, as opposed to traditional rules-based analytics systems that follow explicit instructions.
Big data provides ample amounts of raw material from which machine learning systems can derive insights. By combining them, organizations are producing significant analytics findings and results. However, in order to fully harness the combined power of big data and machine learning, it’s important to first understand what each is and can do on its own. Let’s look at big data vs. machine learning.
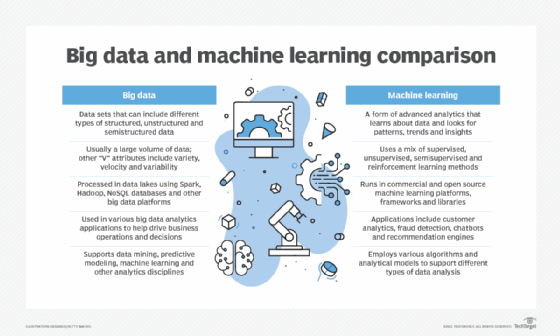
Key differences between big data and machine learning
Big data is, of course, data. The term itself embodies the idea of working with large quantities of data. But data quantity, or volume, is just one of the attributes of big data. Various other “V’s” also must be considered. For example, the following list includes seven V’s:
- Volume. Just dealing with the challenges of storing big data can be a significant undertaking for many organizations. In today’s world, it’s not uncommon for companies to be processing terabytes, petabytes or even exabytes of data daily.
- Velocity. Much of that data is not just static and sitting at rest. In many big data systems, the data is generated, transformed and analyzed at a high velocity. Some big data applications require extremely high processing and analysis speeds, where seconds or milliseconds matter to keep up with the incoming data.
- Variety. Big data comes in various structured, unstructured and semistructured formats. In addition to spreadsheet and transaction data, it’s not uncommon for big data environments to include videos, images, text, documents, sensor data, log files and other types of data.
- Veracity. Because big data typically is collected from a variety of sources, and in a variety of forms, data quality also varies. Veracity refers to the data’s accuracy and trustworthiness. Successfully addressing data veracity challenges requires cleansing data to remove duplicate records, fix errors and inconsistencies, reduce noise and eliminate other irregularities.
- Validity. This builds upon the concept of veracity by focusing on how to apply sets of big data in different use cases. Just because data was generated for one application doesn’t mean it’s applicable to another. Effective data analysis depends on identifying the right data so invalid findings and insights aren’t produced. Likewise, old data might no longer be relevant.
- Visualization. People’s eyes often glaze over when looking at lots of data on a screen. Visualizing large amounts of complex data using charts, graphs, heatmaps and other types of data visualizations is an effective way of conveying insights found in the data.
- Value. At the end of the day, you need to get business value from your data. If you’re doing all the work — and spending all the money — to collect, store, process and analyze sets of big data, you want to be sure your organization is realizing the expected benefits and not simply hoarding data.
Big data analytics is the overall process of exploring and analyzing sets of big data. It incorporates disciplines such as data mining, predictive modeling, statistical analysis and machine learning. The cornerstone of modern AI applications, machine learning provides considerable value to organizations by deriving higher-level insights from big data than other types of analytics can deliver.
Machine learning systems are able to learn about data and adapt over time without following specific instructions or programmed code. In the past, companies built complex, rules-based systems for a vast range of analytics and reporting uses, but they often were brittle and unable to handle continually changing business needs. Now, with machine learning, companies are better positioned to improve their decision-making, business operations and predictive analysis capabilities on an ongoing basis.
Using big data and machine learning together
Big data and machine learning aren’t competing concepts or mutually exclusive. To the contrary, when combined, they provide the opportunity to achieve some incredible results. In fact, successfully dealing with all the V’s of big data helps make machine learning models more accurate and powerful. Effective big data management approaches improve machine learning by giving analytics teams the large quantities of high-quality, relevant data needed to successfully build those models.
Many organizations have already discovered the power of big data analytics enhanced by machine learning. For example, Netflix uses machine learning algorithms to better understand the viewing preferences of individual users and then provide better recommendations, helping to keep people on its streaming platform for longer. Similarly, Google uses machine learning to provide users with a more personalized experience, not only for search but also to build predictive text into emails and give optimized directions to Google Maps users.
The amount of data being generated continues to grow at an astounding rate. Market research firm IDC predicts that 180 zettabytes of data will be created and replicated worldwide in 2025, almost three times more than the 64.2 zettabytes it counted for 2020. As enterprises continue to store and analyze huge volumes of data, the only way they’ll possibly be able to make sense of it all is with the help of machine learning.
Thanks to the work of data scientists, machine learning engineers and other data management and analytics professionals, more companies are using big data, machine learning and data visualization tools together to power predictive and prescriptive analytics applications that help business leaders make better decisions. In the coming years, it will be no surprise if companies that don’t combine big data and machine learning are left behind by competitors that do.




 such as LLAMA-2 and Falcon on Cloud TPUs?")
