Large language models (LLMs), such as ChatGPT, are able to generate human-like, fluent responses for many downstream tasks, e.g., task-oriented dialog and question answering. However, applying LLMs to real-world, mission-critical applications remains challenging mainly due to their tendency to generate hallucinations and their inability to use external knowledge.
This blog introduces our work on LLM-Augmenter, a system that addresses these very issues by augmenting a black-box LLM with a set of plug-and-play modules: Our system makes the LLM generate responses grounded in external knowledge, e.g., stored in task-specific databases. It also iteratively revises LLM prompts to improve model responses using feedback generated by utility functions, e.g., the factuality score of an LLM-generated response.
We validate the effectiveness of LLM-Augmenter using two types of tasks, information-seeking dialog and open-domain Wiki question answering (Wiki QA). Our experiments show that, across all tasks, LLM-Augmenter significantly improves ChatGPT’s groundedness in external knowledge without sacrificing the humanness of its generated responses. For example, on the dialog task of customer service, the human evaluation shows that LLM-Augmenter improve ChatGPT by 32.3% in usefulness and 12.9% in humanness (measuring the fluency and informativeness of model responses). The Wiki QA task is extremely challenging to ChatGPT in that answering these questions often requires multi-hop reasoning to piece together information of various modalities scattered across different documents. Our results show that although the closed-book ChatGPT performs poorly and often hallucinates, LLM-Augmenter substantially improves the factuality score of the answers (+10% in F1) by grounding ChatGPT’s responses in consolidated external knowledge and automated feedback.
We describe this work in more detail in our paper (opens in new tab), and we make its code available on github (opens in new tab).
Overview
LLM-Augmenter improves LLMs with external knowledge and automated feedback using plug-and-play (PnP) modules, as illustrated in the following example:
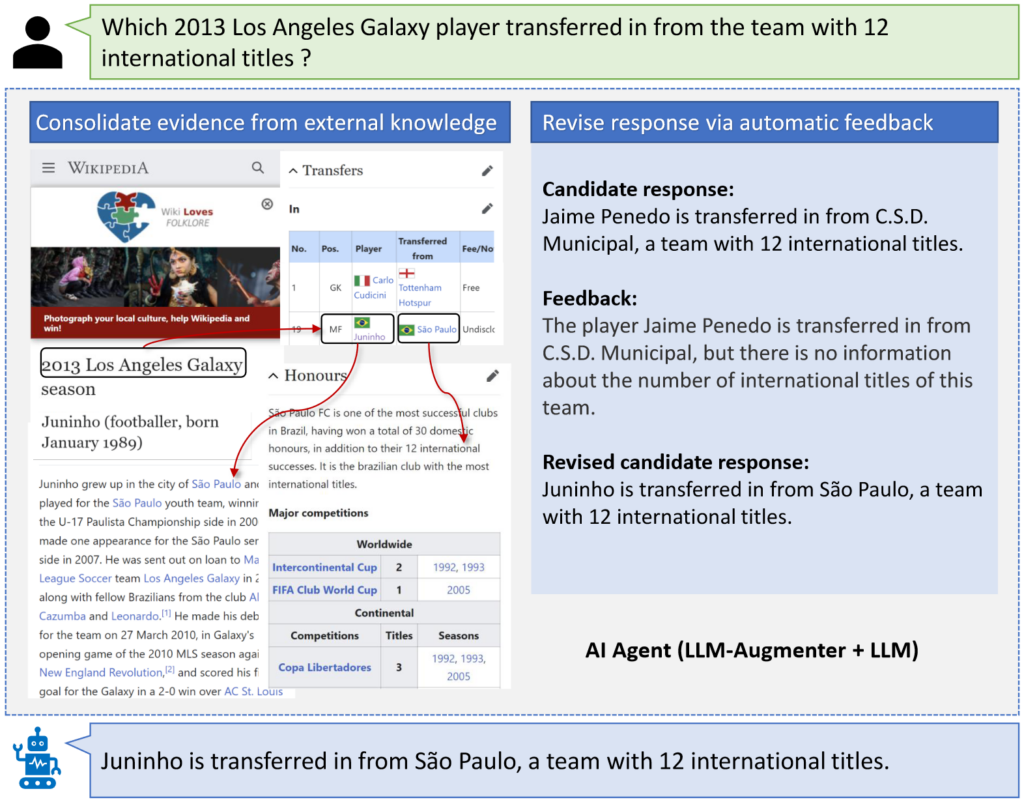
Given a user query (e.g., regarding a 2013 Los Angeles Galaxy player transfer), LLM-Augmenter first retrieves evidence from external knowledge (e.g., Web or task-specific datasets). If necessary, it further consolidates evidence by linking retrieved raw evidence with related context (e.g., information of the entity “2013 Los Angeles Galaxy”) and performs reasoning to form evidence chains (e.g., table-passage in the figure). Then, LLM-Augmenter queries a fixed LLM (i.e., ChatGPT in our work) using a prompt that contains the consolidated evidence for ChatGPT to generate a candidate response grounded in external knowledge. LLM-Augmenter then verifies the candidate response, e.g., by checking whether it hallucinates evidence. If so, LLM-Augmenter generates a feedback message (e.g., about the team “C.S.D. Municipal”). The message is used to revise the prompt to query ChatGPT again. The process iterates until a candidate response passes the verification and is sent to the user.
Architecture
The architecture of LLM-Augmenter is illustrated in the following figure:

LLM-Augmenter consists of a set of PnP modules (i.e., Working Memory, Policy, Action Executor, and Utility) to improve a fixed LLM (e.g., ChatGPT) with external knowledge and automated feedback to mitigate generation problems such as hallucination. We formulate human-system conversation as a Markov Decision Process (MDP) that leverages the following PnP modules:
- Working Memory: tracks the dialog state that captures all essential information in the conversation so far.
- Action Executor: This module performs an action selected by the Policy module. It is composed of two components, the Knowledge Consolidator and the Prompt Engine. The Knowledge Consolidator augments LLMs with the capability of grounding their responses on external knowledge to mitigate hallucination when completing tasks, such as answering questions regarding the latest news, and booking a table in a restaurant. The Prompt Engine generates a prompt to query the LLM.
- Utility: Given a candidate response, the Utility module generates utility score and corresponding feedback using a set of task-specific utility functions (e.g., KF1).
- Policy: This module selects the next system action that leads to the best expected reward. These actions include (1) acquiring evidence from external knowledge, (2) calling the LLM to generate a candidate response, and (3) sending a response to users if it passes the verification by the Utility module.
The policy can be implemented using manually crafted rules or trained on human-system interactions. In our work, we implement a trainable policy as a neural network model, and we optimize it using REINFORCE. The details of our approach and of these PnP modules are provided in the paper.
Results
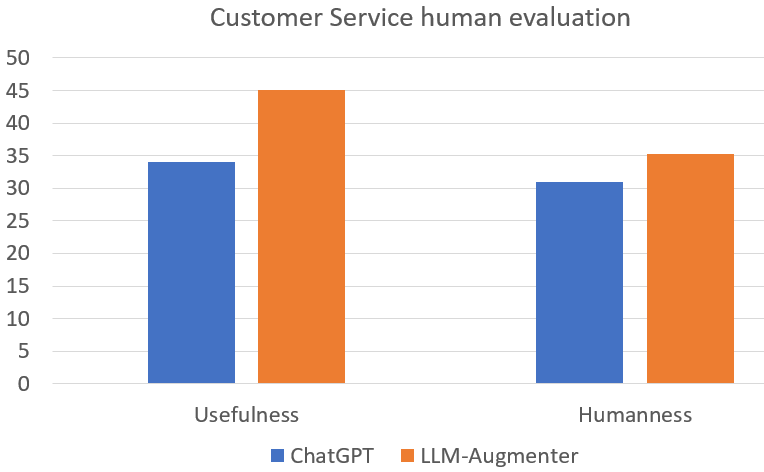
Our paper provides extensive experiments on three tasks, but we focus in this blog on the Customer Support task. We compare ChatGPT with and without LLM-Augmenter A total of about 1,000 randomly selected examples from the customer service dataset are used for human evaluation. We observe a strong preference for LLM-Augmenter over ChatGPT alone in terms of both usefulness and humanness. The result is consistent with the automatic evaluation results provided in the paper.
Examples
The following figure shows real examples comparing ChatGPT with LLM-Augmenter:
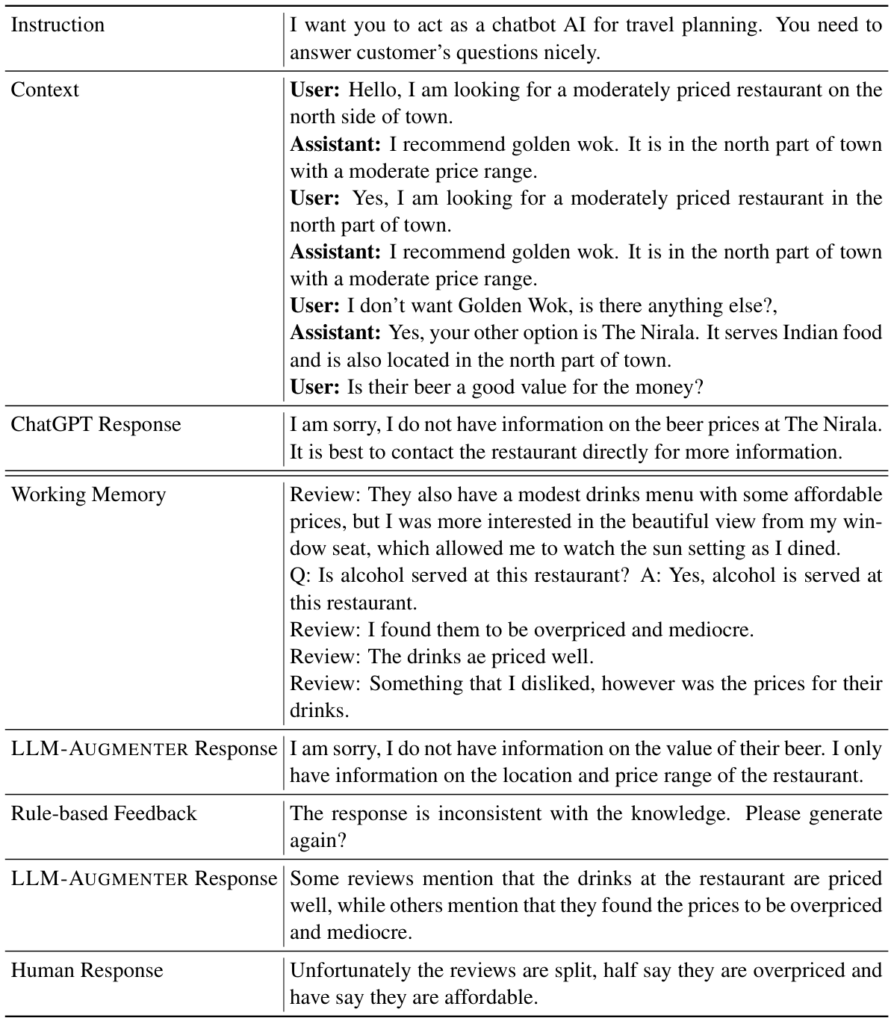
The above table provides sample responses contrasting LLM-Augmenter with ChatGPT. First, we can see that ChatGPT fails to provide a response related to specific knowledge related to the user, e.g., a local Indian restaurant. In the second part of the table, we show LLM-Augmenter’s Working Memory, which highlights the richer information retrieved from external knowledge to help the underlying LLM (i.e., ChatGPT as well) generate more contentful responses. The first LLM response received by LLM-Augmenter is unfortunately not satisfactory, as the quality and specificity of LLM generation can be unpredictable. In this case, the Utility module has determined that the first response did not meet its criteria (i.e., KF1 above a given threshold), and issues feedback to the LLM module (i.e., “response is inconsistent with the knowledge”). The second response received by LLM-Augmenter is much more satisfactory according to the utility function and therefore sent to the user.
Acknowledgments
This research was conducted by Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, Jianfeng Gao at Microsoft Research. We also thank Saleema Amershi, Ahmed Awadallah, Nguyen Bach, Paul Bennett, Chris Brockett, Weixin Cai, Dhivya Eswaran, Adam Fourney, Hsiao-Wuen Hon, Chunyuan Li, Ricky Loynd, Hoifung Poon, Corby Rosset, Bin Yu, Sheng Zhang, and members of the Microsoft Research Deep Learning group for valuable discussions and comments.





