ChatGPT’s emergence not only renewed interest in artificial intelligence, but arguably sparked an unprecedented wave of advancements in AI technology. One such advancement takes the form of universal large language models (LLMs), which were previously difficult for the AI community to create. That problem is now passe. Instead, the next hurdle to overcome is determining how to effectively implement such models in practical applications.
Chinese AI firm Baichuan Intelligent Technology has seemingly made a significant leap in this regard. In October last year, Baichuan unveiled Baichuan2-192K, a large model capable of processing around 350,000 Chinese characters. That’s roughly 14 times the size of OpenAI’s GPT-4 and approximately 4.4 times that of Anthropic’s Claude 2, which has drawn plaudits for its excellence in processing long-form text.
On December 19, Baichuan launched the search-focused Baichuan2-Turbo series API, which includes Baichuan2-Turbo-192K and Baichuan2-Turbo.
Baichuan has also upgraded its official web-based models. Enterprise users can now upload various text formats such as PDFs, word documents, and URLs into the API to experience the enhanced capabilities of the Baichuan2 large model.
A large model “plug-in” to build knowledge bases instantly
Baichuan views large models as the computers of the new era, in some ways akin to central processors. The context window is likened to the computer’s memory, storing the text to be processed. The real-time information of the internet and the knowledge base of enterprises collectively form the equivalent of a computer’s hard drive.
The company’s newly introduced API enables large models to “attach” external knowledge bases, according to CEO Wang Xiaochuan.
While LLMs have become the infrastructural foundation of the AI era, the technical exploration of these models is still in its infancy. Despite the increase in model parameters, challenges persist—such as the hallucination problem and the issue of queries being “forgotten.” These limitations significantly impede the efficiency of large models.
However, the usability of large models can be augmented by combining them with search-related enhancements, Wang said. This enables even models with fewer parameters to handle much larger volumes of text in a single query, and at faster speeds.
To demonstrate the effectiveness of this approach, Baichuan tested the Baichuan-192K API using the classic “needle in a haystack” test:
- Place a random fact or statement (the “needle”) in the middle of a context window (the “haystack”).
- Ask the model to retrieve this fact or statement.
- Iterate this process over various document depths (where the “needle” is placed) and context lengths to determine the model’s performance.
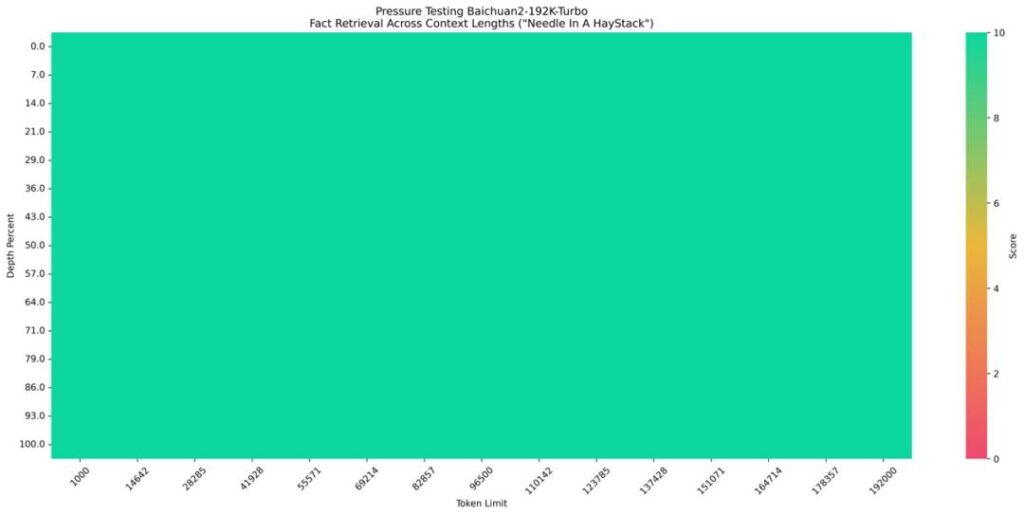
For requests that fall within the 192K’s token limit, 100% answer accuracy can be achieved. With the latest enhancement, Baichuan2 can handle a new maximum of 50 million tokens, which is equivalent to 350,000 Chinese characters—two orders of magnitude larger than before.
Baichuan also evaluated the effectiveness of pure vector retrievals as well as a combination of vector and sparse retrievals. The results indicate that the combined approach can achieve 95% answer accuracy. With a roughly 250-fold increase in the total volume of handleable text, the recall accuracy has also improved to 95%.
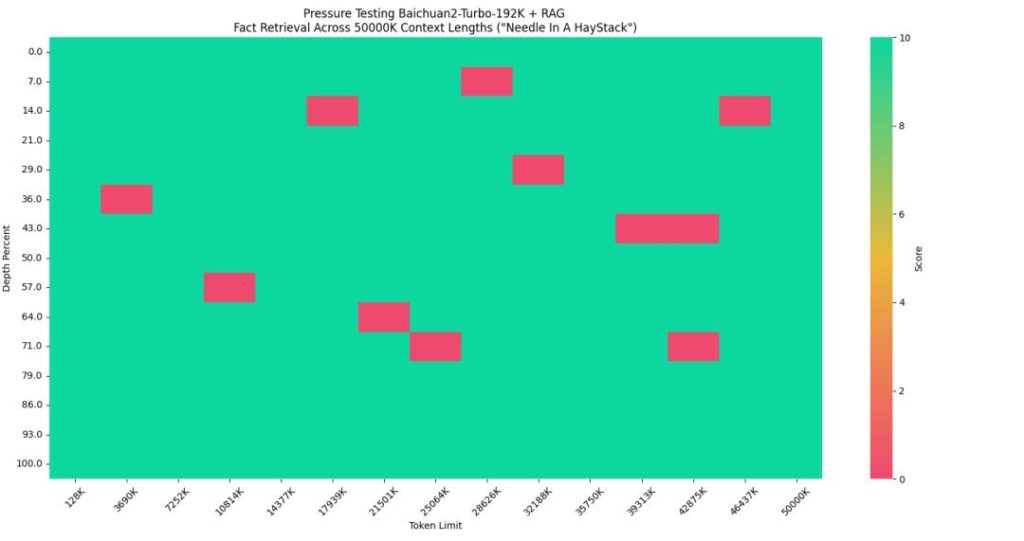
Specifically, Baichuan conducted the test by using the following configuration (in Chinese):
- Haystack: 80 long-form financial documents from a dataset used for the 2023 Bojin Large Model Challenge.
- Needle: On December 16, 2023, during the GeekPark Innovation Conference 2024, Wang Xiaochuan shared new insights into large models. In his view, with the advent of the large model era, the starting point for product managers should shift from considering product-market fit (PMF) to considering technology-product fit (TPF).
- Query: According to Wang Xiaochuan, what is the starting point for product managers in the era of large models?
This release marks a further improvement in the operational speed and accuracy of large models. Even with extensive context, Baichuan’s test results demonstrate that LLMs can now operate effectively with updated data, faster, more accurately, and at a significantly lower cost than building industry-specific models.
Customization does not equate to verticalization
In addition to the new API, Baichuan has introduced a search enhancement knowledge base. Its utility is straightforward: companies upload privately deployed data and information to the cloud, generating a customized system that integrates with Baichuan2 in a plug-and-play fashion.
The current Baichuan2 can be deployed in various B2B scenarios, including customer service, knowledge Q&A, compliance risk control, and marketing and consulting in industries such as finance, government, legal, and education.
During the launch event, Baichuan presented a sample scenario in the finance industry. In this example, a bank’s knowledge base was cited to comprise 6 terabytes of data, with 12,905 documents. The presentation describes Baichuan2’s ability to efficiently retrieve information from this extensive base—by inputting a document with 360,000 words into the model through the API, precise answers can be obtained.
The method of combining LLMs with search enhancement technology provides a practical path for the future implementation of large models in various industries.
Enterprise knowledge bases are currently the mainstream use case for LLMs. Previously, building such bases required large models to be pre-trained—a process that typically required highly skilled AI professionals. Any updates to the underlying data would also require retraining or fine-tuning, which can be costly and affect controllability and stability..
Another challenge lies in vector retrieval, as the overall cost of utilizing vector databases is relatively high. Their effectiveness depends on the scale of training data, with a noticeable discount in general capability for areas not covered by training data. The difference between user prompts and document lengths in the knowledge base also poses significant challenges to vector retrieval.
In this regard, Baichuan’s combination of LLMs with search enhancement technology has solved some technical challenges. It pioneered the self-critique large model technique using general retrieval-augmented general (RAG) technology as a foundation, allowing LLMs to evaluate their own answers before outputting them to users, selecting answers with the highest quality in the process.
This approach could replace the majority of custom fine-tuning techniques currently adopted by enterprises, while addressing 99% of the customization needs of enterprise knowledge bases.
While Wan admitted that customization is unavoidable in the industrial implementation of LLMs, the delivery capability can be continuously improved through technical iterations.
With the latest release, Baichuan highlights its rapid advance toward commercial implementation. The company has also revealed that it has entered into partnerships with leading enterprises in various industries for further development, but did not go into detail on the specifics of these collaborations.
KrASIA Connection features translated and adapted content that was originally published by 36Kr. This article was written by Yong Yi for 36Kr.




