06 May 2024
Introduction
If you are into AI or futurism, it’s pretty hard to avoid conversations about AGI. When will we achieve AGI? What will AGI be like? Will AGI end the human race? This is a little frustrating, because I think a lot of the energy being put into thinking about and working towards AGI is being wasted. To be clear, I’m not an AI doomer, I’m very much on the “AI will change the world” bandwagon, I just think people are approaching the problem the wrong way.
The Problem with AGI
People throw the term AGI around, but it lacks a clear definition that we can rally around. It could range from “smarter than the average human at most things” all the way to “smarter than the smartest humans at everything we can measure.” If we use the weak definition, our current language models are arguably AGI. If we use the strongest definition, we might never achieve AGI since the smartest humans will be able to use the AI as a tool and stand on its shoulders for better results than the AI could achieve alone in most cases. Additionally, I think the intelligence of the model creators biases the intelligence of the training corpus in an unavoidable and limiting way.
To be clear, I’m not saying that model creators can’t create data sets that are more intelligent than they are, but it is unavoidable that creating such a data set will be a trial and error process as the model creators lack the ability to accurately assess superhuman intelligence a priori. That means that as AI approaches peak human intelligence we will have to resort to large scale data generation and a global optimization algorithm to select the best data set over time in order to continue progressing. That will probably keep things moving slowly, however I expect the progress drop off to be brutal as using optimization to explore the space of superintelligent models is definitely much slower than bootstrapping from human abilities which are themselves the result of genetic algorithms over geological time scales. I imagine that some of the cost of running these data set experiments could be mitigated by the right architecture and training techniques, so if you want to get ahead of the curve consider how you could reduce the cost of trying and comparing various different combinations of data during training.
There are cases where models learn to be “superhuman” such as AlphaGo and the other reinforcement learning projects from DeepMind, but these are specialized tools and the most “superhuman” thing about them is the amount of energy they consume to outperform humans. Reinforcement learning is no different than a person experimenting while practicing a skill, I suspect AlphaGo has probably played several orders of magnitude more games than any living human go player, and since it wasn’t stuck in the local optimum of human go strategies it was able to come up with some very original tricks. A human could have come up with those tricks, but we have limited time to invest in experimentation so we tend to select safe experiments, whereas a bot with reinforcement learning and a trillion dollar company footing the compute bill can try all sorts of stupid shit on the small chance that it might be accidentally brilliant.
These reinforcement learning systems aren’t so much a path to AGI as specialized knowledge creation engines for domains with a succinctly describable objective. You might argue that this approach could be scaled to create AGI, but it has the same problem as language models – the intelligence of the model is limited by the intelligence of the model’s creators. In language models, the problem is assembling a superhuman corpus of training data, with reinforcement learning the problem is creating a superhuman objective. You might suggest a variation of the same trick I talked about before – using another model to come up with the AGI objective, but I suspect that is just shuffling the complexity around rather than actually solving the problem. Perhaps we could throw enough compute at the problem to solve it using the “infinite monkeys on infinite typewriters produce the complete works of Shakespeare” strategy, but there’s a reason people use that meme pejoratively.
AGI Maybe never?
In fact, to strengthen the argument that if AGI means “better than the smartest humans at literally everything,” there’s a good chance we will never achieve it, I want to call attention to something that futurists tend to miss – specifically that progress isn’t exponential, but sigmoidal. Exponential growth is impossible in any finite system – as the system approaches the limits of its capacity, growth becomes logarithmic. That means you can get to 80% of the limit of a sigmoidal function in pretty short order, but getting to 99% or 99.999% is a very different feat. The people who’ve worked on self-driving cars know what I’m talking about – the core technology has been functional for ~15 years but we’re still getting crushed by the long tail complexity of the real world task. We’re going to run into this phenomenon again and again as we create tools to automate various aspects of human behavior.

Furthermore, the “no free lunch theorem” (NFLT) becomes more of an issue the more general your model becomes. In simple terms, the NFLT states that there is no single model or algorithm that can outperform all others across all possible tasks or datasets. Think of it like a restaurant menu – just as there is no single dish that is the best choice for every person, every time, there is no single model that is the best choice for every problem, every time. Inductive biases that improve inference for one set of problems will necessarily make it worse for others. Eventually trying to make one model good at everything is going to become a game of whack-a-mole with endless performance regressions unless you submit to parameter explosion.

If you want to see the no free lunch theorem in action, just look at how OpenAI “lobotomized” ChatGPT – they optimized it to be better at logic and question answering and it caused a significant deterioration in its creative writing skills. Likewise, if you look at the current generation of Llama3 fine tunes, they also tend to show deterioration in high level logic and reasoning in exchange for better role play abilities. That sort of “robbing Peter to pay Paul” effect is going to become more common as models become more optimized, which means monolithic models will have to get much larger to be superhuman at more things. That isn’t efficiently scalable even if we assume better architectures, so specialization is the likely reality. Finally, model intelligence seems to scale logarithmically with additional parameters serving more to bake in knowledge than increase intelligence, so it’s questionable how viable larger monolithic models are as a strategy anyhow.
A Task-Centric Approach to AI
So, if AGI is a red herring and trying to build more and more intelligent monolithic models to reach AGI is a fool’s errand, what should we be doing instead? I’d like to propose that we stick to a task-centric view of AI – given a specific task, how well does the model perform the task compared to average and optimal human performance? This is a very straightforward problem to understand, and achieving near optimal human performance is much easier when the bounds of the task are constrained. If there’s a task current models don’t do well, we can funnel resources into creating new models that can perform that task.
I can imagine a lot of readers are bristling at this suggestion, but there’s a very good reason for it. If there is a specialized tool for every known task a human might undertake that achieves near human optimal performance, the task of creating “AGI” becomes the task of creating an agent that is just smart enough to select the right tools for the problem at hand from a model catalog and large language models are pretty close to that level already. This approach also leaves the tools accessible to humans rather than hiding them away in a giant model, and if new tasks emerge or existing tasks change you don’t need to retrain that giant model to be good at them – just update the model catalog with a new specialized tool.
Beyond the benefits I just mentioned, this path has the benefit of being clearly evaluable and more tractable to solve. If we managed to create AGI in a monolithic manner, we would still need a vast suite of benchmarks encapsulating all the tasks humans are capable of in order to prove that it was “AGI.” Since we need this exhaustive suite of benchmarks anyhow, why not just build to that in the first place? Any engineer worth their salt can tell you that a system with thousands of functions that each do one thing well is easier to build and maintain than a system with one function that can do thousands of things when invoked with the correct arguments.
The Path Forward
So, if we’re really serious about building AGI, what should we be doing today?
-
The first thing we need is an improved suite of truly exhaustive benchmarks. If our definition of AGI is “better than most humans at everything,” we can’t even make coherent statements about that until we have the ability to measure our progress, and a deep benchmark suite is the starting point. This will entail moving beyond simple logical problems to complex world simulating scenarios, adversarial challenges and gamification of a variety of common tasks.
-
Secondly, stop trying to train supermodels that know everything, pick a problem domain that AI isn’t good at yet and really hammer it with specialized models until we have tools that match or exceed the abilities of the best humans in that area. If you really want to push the boundaries of general foundation models, consider working on making them more efficient or easily tuneable/moddable. I also think there is a lot of low hanging fruit in transfer learning between languages, and any improvements there will make models better at coding and math as a side effect.
-
Finally, we need to design asynchronous agents that are capable of out of band thought/querying and online learning (in the optimization sense) and have been trained to identify sub-problems, select tools from a catalog to answer them, then synthesize the final answer from those partial answers. The agent could convert sub-problems into embeddings then use their positions in embedding space to select the models to process them with. I suspect this agent could be created with a multimodal model having a “thought loop” which can trigger actions based on the evolution of its objectives over time, with most actions being tool invocations producing output that further informs those objectives.
There is very little uncertainty in this path, no model regressions, no measurement problem and no need for supergenius engineers, only the steady ratcheting of human cultural progress. Beyond that, this method will put the whole “when will we have AGI” debate to bed because we’ll be able to track the coverage of tasks where AI is better than human, we’ll be able to track the creation of new tasks and the rate at which existing tasks fall to AI and use a simple machine learning predictor to get a solid estimate for the exact date when AI will be better than humans at “everything.”
The Sibylline Circle
Just to give you an idea of how we can track this progress in a way that’s easy for humans to quickly grok, here’s an example visualization. Imagine that each bar is a benchmark for a specific task:
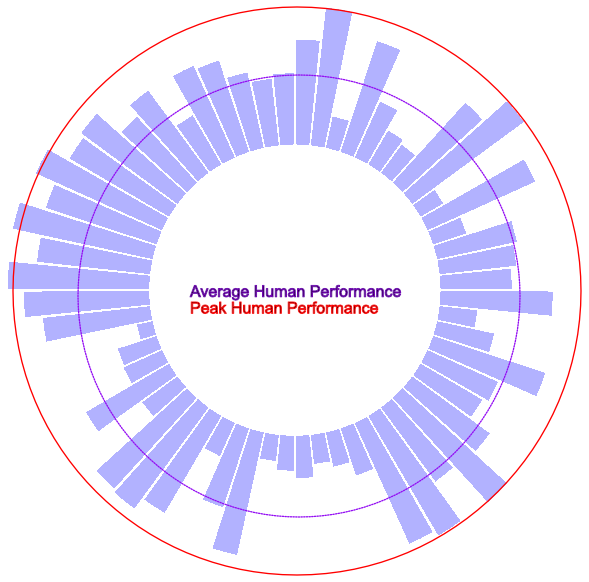
Over time the number of individual benchmarks is likely to get so large that the chart needs to be rendered as a line chart rather than bars, but to avoid losing information, benchmarks could be clustered and sorted based on topic/type of task/etc with coloring for each cluster so that the chart is still easily interpretable.
Since I’ve always wanted to name something in public discourse, I’m going to call this measure of AGI progress the “sibylline circle.” Since AI is oracular in both senses and sibylline can also indicate a double meaning, I think it fits and it’s a fair bit of self promotion.
Note that the sibylline circle could also be a useful tool for people using AI, as it would make identifying the areas where AI is unreliable easier.
")



