Note: “SOTA” stands for state-of-the-art, referring to the most advanced and effective models currently available in the field.
Exactly a year ago, ChatGPT was one month old, Anthropic just released Claude, and Microsoft unveiled the first zero-shot model to clone someone’s voice. Long before Google Bard’s debut, Stanford’s inaugural autonomous agents paper, and the incorporation of the video-generating startup Pika Labs.
In 2023 alone, more than 1,100 curated announcements and papers were featured in AI Tidbits. It is hard to keep up with such mind-boggling progress when hundreds of innovative papers are published every single week, yet it is easy to forget the leapfrog progress the AI community has realized in just one year.
Just before we yell at ChatGPT once again as it got one detail wrong, let’s review the state-of-the-art today compared to December 2022 across different generative AI verticals.
2023 was the year open-source language models started catching up, with Yi’s 200k context window and Mistral’s Mixture of Experts outperforming GPT-3.5, which was the SOTA just earlier this year.
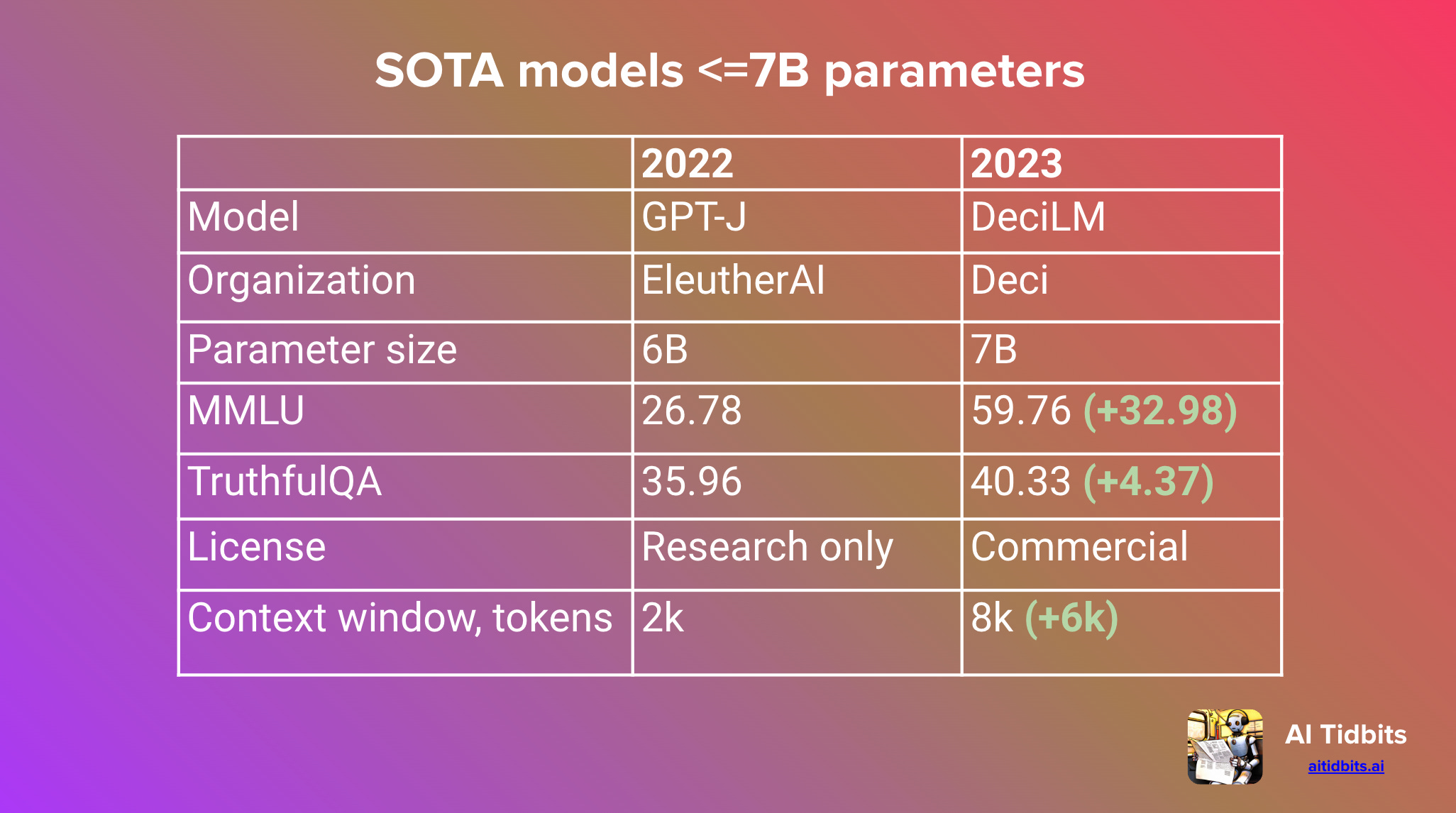
Commercially permissive models with groundbreaking architectures such as Llama 2 gave birth to advanced models like Code Llama and whole new model families such as Vicuna. Small language models also had their moment, yielding dozens of tokens per second on consumer-grade devices.
Despite the significant advancements in open-source models in 2023, the evaluation of language models has yet to achieve consensus, and the AI community’s trust in researchers’ published benchmarks is at an all-time low.
Our report therefore only includes community-vetted LLMs or ones I’ve tinkered with and can vouch for. You can find the full list of almost 1,000 open-source language models on Hugging Face’s Open LLM Leaderboard.
As for the benchmarks I’ve considered as the performance proxy, I chose MMLU for its wide-ranging evaluation of language understanding across various domains and TruthfulQA to assess the AI’s ability to provide factual and reliable information, ensuring a comprehensive analysis of both depth and accuracy.
Mistral’s recently released Mixtral 8x7B model deserves a special shout-out. It is a Mixture of Experts (MoE) model that outperforms Llama 2 70B and GPT-3.5 on most benchmarks with 6x faster inference. It allows commercial use and judging on its predecessor, Mistral 7B, we can expect a host of Mixtral-based state-of-the-art language models coming in the next few months.
While the language models mentioned above are the state-of-the-art ones today, there are further noteworthy models released in 2023 that paved the way for these models to emerge: Flan-UL2, Llama 2, MosaicML MPT, Falcon, Vicuna, Dolly, phi 1.5, Orca 2, and WizardLM.
Just listing these models made me realize what a monumental year 2023 was for open-source language models, and we are scratching the surface of what’s possible–most of these models are base models, i.e. they can be further fine-tuned for specific tasks to boost accuracy and achieve a smaller model size.

Surprisingly enough, GPT remained SOTA throughout 2023, with Gemini Ultra emerging as the only potential contender a few weeks ago, claiming to outperform GPT-4 across several benchmarks. However, given the divide between Gemini Pro’s proclaimed and actual capabilities, such supremacy remains doubtful.
Anthropic also made great progress with its release of Claude 2.1, featuring the largest context window for proprietary LLMs (200k) at a substantially lower price than GPT-4.
🌟 New Years - become a premium member to access $1k in credits for top AI tools, monthly AI round-ups, and deep dives into key topics like advanced prompting techniques and methods to mitigate hallucinations.
Many readers expense AI Tidbits out of their learning and development budget, which resets in a few weeks due to year end (expense template).Multimodal AI refers to AI systems that can process and interpret multiple forms of data input, such as text, images, and audio, simultaneously or in an integrated manner, very much like humans.
Models specialized for a single modality, such as images or text, are limited in their capabilities and require much more training data. This contrasts with human learning, in which people learn much more efficiently thanks to different kinds of sensory inputs.
Progress in this space is paramount because it enables more sophisticated, efficient, and accurate AI applications and powers the next generation of wearables and embodied robotics.
2022 was relatively quiet for multimodal AI. The only major release was Meta’s data2vec, a model operating across multiple modalities, including speech, images, and text.
2023 saw several breakthrough models and frameworks, with CogVLM crowned as the SOTA open-source model.
CogVLM outperformed all previous models, such as LLaVA 1.5, an open-source chatbot alternative to ChatGPT that can converse using images and text, and Adept’s Fuyu, capable of understanding charts, documents, and interfaces. Meta also made significant contributions through its ImageBind and AnyMAL papers.

On the proprietary front, GPT-4V(ision) is the current industry leader, showcasing strong performance. Gemini Ultra seems like a close runner-up, though hard to tell as Google hasn’t opened developers access yet.


An autonomous agent is an AI program capable of planning and executing tasks based on a given objective. Imagine asking an AI to “book a flight” or “create a website for people interested in renting their apartments when they’re away” – and the agent goes to work.
It does so by repeatedly asking “What should be the next steps to achieve the task at hand”, utilizing an LLM to answer this question and devise a plan to execute.
AI Agents that can do work for us is a great promise. In 2022, the main player was Adept with its ACT-1 model. Although mainly a demo, Adept showcased an agent that can find apartments on Redfin, take actions on Google Sheets, and input information into Salesforce using natural language.
On the contrary, 2023 was filled with open-source and commercial progress. Stanford’s Simulacra paper ignited everyone’s imagination and created innovative frameworks for agent builders (AutoGPT, BabyAGI) and agent-based applications (GPTEngineer, MetaGPT).
To date, the open-source SOTA model is CogAgent (demo), a powerful 18B visual language model capable of navigating mobile applications and websites, surpassing existing LLMs in both text and general VQA benchmarks.

There is still no clear winner on the commercial front. The leading startups operating in this space include Adept, Embra, Lindy, Induced, and HyperWrite AI. As the language models powering such agents become increasingly cheaper and more competent, 2024 might be the year of the first widely-used agent, our first AI companion.

Image generation is the verticle having the most notable progress across modalities. Over the past two years, the transformation has been astounding, evolving from artificial-looking creations to artistry so professional it is virtually indistinguishable from human work.
2022 was the year in which image generation steered away from GANs and onto Diffusion models. In one buzzing summer, DALL-E 2, Stable Diffusion, and Midjourney were released, sending the image synthesis space off to the races. In the eighteen months since these releases, both the open-source and commercial models have undergone massive improvements.
Given the subjective nature of art, pinpointing a definitive 2023 SOTA is challenging. However, OpenAI’s DALL-E 3 and Midjourney are the reigning champions, distinguished by their widespread usage and consistently high-quality outputs. In 2023, these image generation models overcame a significant hurdle that plagued image diffusion models in 2022: the accurate rendering of faces, hands, and text.

DALL-E 3 has introduced several advances over its 2022 predecessor with improved caption fidelity, overall image quality, and better steerability to reduce the generation of harmful images, demographic biases, and public figures.
In 2023, Midjourney graduated from Discord onto a web app and jumped from v5 to v6, showcasing notable improvements in detail and text generation capabilities.

Other noteworthy step changes include Stability AI’s SDXL Turbo, supporting high-resolution image generation at a fraction of the compute and cost, and Ideagram, which made the rounds with their text generation capabilities, a differentiating feature before DALL-E 3 was released.

On the open-source front, we got Fooocus, a package that allows everyone to generate Midjourney-quality images on their own computer without needing the advanced prompting techniques employed by Midjourney experts.
Generation latency has also substantially reduced thanks to novel techniques such as Latent Consistency Models (LCM), supporting real-time image generation at typing speed.
Generative models in video weren’t really a thing in 2022. The space was practically dormant, with merely a teaser from Runway about its upcoming text-to-video model Gen-1 and a few closed releases such as Google’s Imagen Video and Meta’s Make-A-Video.
This has changed in 2023, with numerous open-source packages emerging and notable advancements in commercial products, including an extended maximum video duration of 18 seconds (up from 4 seconds in 2022), alongside substantial enhancements in video quality and consistency.
On the commercial front, Pika Labs and Runway lead the pack, both developing their own foundation text-to-video models. This year, they added video inpainting and outpainting capabilities and the ability to render styles like anime and cinematic.
Another notable contender is HeyGen, which uses AI to translate videos into almost 30 languages by cloning the speaker’s voice and adjusting lip movements to the target language.
On the open-source front, VideoCrafter1 and ModelScope are the current state-of-the-art models. VideoCrafter1 can generate realistic and cinematic-quality videos from text with a resolution of 1024 × 576, outperforming previous open-source models in terms of quality. It features another image-to-video model designed to produce videos that strictly adhere to the content of the provided reference image. ModelScope can generate videos up to 25 seconds long at a reasonable quality.
Also this year, Stability AI released Stable Video Difussion, turning images into short video clips, though permitting research use only.
Lastly, just before year-end, Meta released Emu Video, capable of efficiently generating high-quality, 512px, 4-second long videos, conditioned on text prompts and initial generated images, outperforming other state-of-the-art text-to-video models like Runway and Pika in terms of video quality and faithfulness to prompts.

Transcribing sound and audio has been predominantly human-driven up until recently.
OpenAI’s release of Whisper in 2022, back then the SOTA open source transcription model, reignited the space and fostered a wave of speech-powered applications.
Since then, two more Whisper versions have been released in 2023, supporting 58 languages with reduced hallucinations and a 10%-20% lower Word Error Rate (WER). Thanks to packages such as Insanely Fast Whisper, inference latency has also been reduced to near real-time, enabling live conversational use cases.
The current commercial SOTA speech-to-text model is Nova-2 from Deepgram. It outperforms all alternatives in terms of accuracy, speed, and cost and achieves an 8.4 WER, 30% less than its 2022 predecessor.
The space of generative voice AI didn’t see much progress until this year, with incumbents like Amazon and Google providing ok-ish solutions.
In 2023, ElevenLabs wowed the industry with its remarkably fast text-to-speech model, outperforming all other models on latency and quality. AI-generated voice is no longer distinguishable from human voice. As competition heats up in this space with contenders such as OpenAI’s TTS, we can expect better and more affordable models in 2024.
Joe Biden’s voice cloned via ElevenLabs (source)
The open-source community is not far behind. Meta open sourced Seamless–a suite of AI translation models that can generate and translate speech in real-time.
Microsoft also introduced VALL-E X (open-source implementation), capable of synthesizing high-quality speech with only a 3-second enrolled recording of an unseen speaker as input, and Coqui released XTTS – a voice generation model capable of cloning voices into 17 different languages by using a 6-second audio clip.
2022 ended with the release of Riffusion, an app that generates music from text using visual sonograms.
Like other generative AI vertices, 2023 was different. On the open-source front, Meta’s MusicGen demonstrated remarkable performance, turning text and melodies into music. MusicGen’s release was complemented with Amphion – an open-source toolkit for audio, music, and speech generation released a few weeks ago.
On the commercial side, Suno AI is the prominent industry leader, with Stable Audio and Google’s MusicFX as runner-ups. Suno generates original songs with lyrics and melody, all from text prompts and within a few minutes. To fully appreciate how far we have come, I strongly recommend experimenting with Suno through its web application or by using Microsoft Copilot.
In eight months, Suno extended song duration into full-length songs and added lyrics generation capabilities. April ‘23 (top) compared to Dec ‘23 (bottom):








If you find AI Tidbits valuable, share it with a friend and consider showing your support.

