Large multimodal models (LMMs) represent a significant breakthrough, capable of interpreting diverse data types like text, images, and audio. However, their complexity and data requirements pose potential challenges. Innovations in AI research are aiming to overcome these challenges, promising a new era of intelligent technology.
In this article, we explain large multimodal models by comparing them to large language models.
What is a large multimodal model (LMM)?
A large multimodal model is an advanced type of artificial intelligence model that can process and understand multiple types of data modalities. These multimodal data can include text, images, audio, video, and potentially others. The key feature of a multimodal model is its ability to integrate and interpret information from these different data sources, often simultaneously.
These can be understood as more advanced versions of large language models (LLMs) that can work not only on text but diverse data types. Also, multimodal language model outputs are targeted to be not only textual but visual, auditory etc.
Multimodal language models are considered to be next steps toward artificial general intelligence.
What is the difference between LMMs and LLMs?
1- Data Modalities
- LMMs: They are designed to understand and process multiple types of data inputs, or modalities. This includes text, images, audio, video, and sometimes other data types like sensory data. The key capability of LMMs is their ability to integrate and make sense of these different data formats, often simultaneously.
- LLMs: These models are specialized in processing and generating textual data. They are trained primarily on large corpora of text and are adept at understanding and generating human language in a variety of contexts. They do not inherently process non-textual data like images or audio.
2- Applications and Tasks
- LMMs: Because of their multimodal nature, these models can be applied to tasks that require understanding and integrating information across different types of data. For example, an LMM could analyze a news article (text), its accompanying photographs (images), and related video clips to gain a comprehensive understanding.
- LLMs: Their applications are centered around tasks involving text, such as writing articles, translating languages, answering questions, summarizing documents, and creating text-based content.
What are the data modalities of large multimodal models?
Text
This includes any form of written content, such as books, articles, web pages, and social media posts. The model can understand, interpret, and generate textual content, including natural language processing tasks like translation, summarization, and question-answering.
Images
These models can analyze and generate visual data. This includes understanding the content and context of photographs, illustrations, and other graphic representations. Tasks like image classification, object detection, and even creating images based on textual descriptions fall under this category.
Audio
This encompasses sound recordings, music, and spoken language. Models can be trained to recognize speech, music, ambient sounds, and other auditory inputs. They can transcribe speech, understand spoken commands, and even generate synthetic speech or music.
Video
Combining both visual and auditory elements, video processing involves understanding moving images and their accompanying sounds. This can include analyzing video content, recognizing actions or events in videos, and generating video clips.
Although most multimodal large language models today can only use text and image, future research is directed at including audio and video data inputs.
How are large multimodal models trained?
For better understanding, training a multimodal large language model can be compared to training a large language model:
1- Data Collection and Preparation
- LLMs: They primarily focus on textual data. The data collection involves gathering a vast corpus of text from books, websites, and other written sources. The emphasis is on linguistic diversity and breadth.
- LMMs: In addition to textual data, these models also require images, audio, video, and potentially other data types like sensory data. The data collection is more complex, as it involves not just a variety of content but also different formats and modalities. Data annotation and normalization are crucial in LMMs to align these different data types meaningfully.
2- Model Architecture Design
- LLMs: They typically use architectures like transformers that are suited for processing sequential data (text). The focus is on understanding and generating human language.
- LMMs: The architecture of LMMs is more complex, as they need to integrate different types of data inputs. This often involves a combination of neural network types, like CNNs for images and RNNs or transformers for text, along with mechanisms to fuse these modalities effectively.
3- Pre-Training
- LLMs: Pre-training involves using large text corpora. Techniques like masked language modeling, where the model predicts missing words in sentences, are common.
- LMMs: Pre-training is more diverse, as it involves not just text but also other modalities. The model might learn to correlate text with images (e.g., captioning images) or understand sequences in videos.
4- Fine-Tuning
- LLMs: Fine-tuning is done using more specialized text datasets, often tailored to specific tasks like question-answering or translation.
- LMMs: Fine-tuning involves not only specialized datasets for each modality but also datasets that help the model learn cross-modal relationships. Task-specific adjustments in LMMs are more complex due to the variety of tasks they are designed for.
5- Evaluation and Iteration
- LLMs: Evaluation metrics are focused on language understanding and generation tasks, like fluency, coherence, and relevance.
- LMMs: These models are evaluated on a wider range of metrics, as they need to be adept in multiple domains. This includes image recognition accuracy, audio processing quality, and the model’s ability to integrate information across modalities.
What are some famous large multimodal models?
- CLIP (Contrastive Language–Image Pretraining) by OpenAI: CLIP is designed to understand images in the context of natural language. It can perform tasks like zero-shot image classification, where it can accurately classify images even in categories it hasn’t explicitly been trained on, by understanding text descriptions.1
- Flamingo by DeepMind: Flamingo is designed to leverage the strengths of both language and visual understanding, making it capable of performing tasks that require interpreting and integrating information from both text and images.2
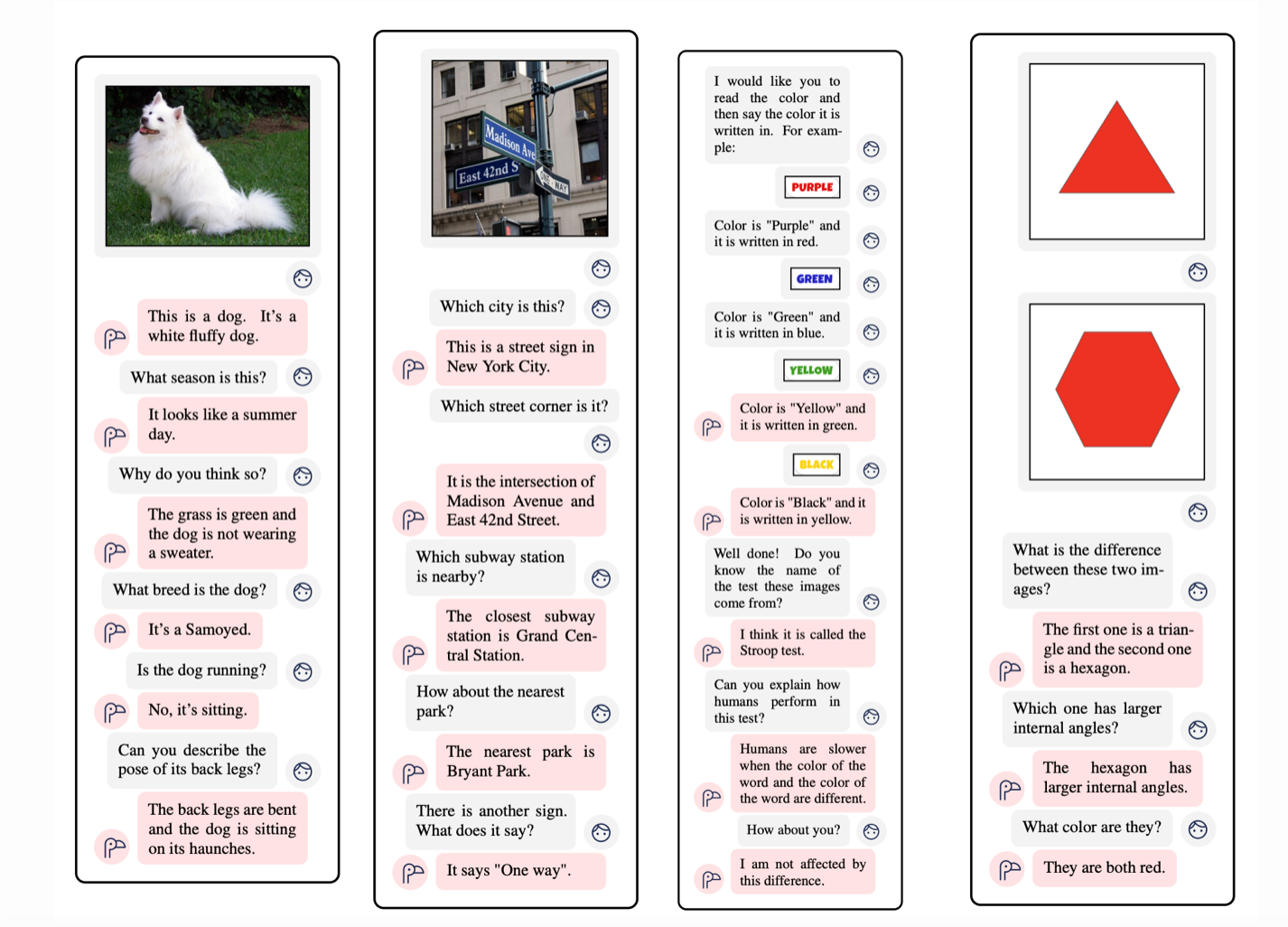
Source: Chip Huyen3
What are the limitations of large language models?
- Data Requirements and Bias: These models require massive, diverse datasets for training. However, the availability and quality of such datasets can be a challenge. Moreover, if the training data contains biases, the model is likely to inherit and possibly amplify these biases, leading to unfair or unethical outcomes.
- Computational Resources: Training and running large multimodal models require significant computational resources, making them expensive and less accessible for smaller organizations or independent researchers.
- Interpretability and Explainability: As with a complex AI model, understanding how these models make decisions can be difficult. This lack of transparency can be a critical issue, especially in sensitive applications like healthcare or law enforcement.
- Integration of Modalities: Effectively integrating different types of data (like text, images, and audio) in a way that truly understands the nuances of each modality is extremely challenging. The model might not always accurately grasp the context or the subtleties of human communication that come from combining these modalities.
- Generalization and Overfitting: While these models are trained on vast datasets, they might struggle with generalizing to new, unseen data or scenarios that significantly differ from their training data. Conversely, they might overfit to the training data, capturing noise and anomalies as patterns.
For more content on the challenges and risks of generative and language models, check our article.
If you have questions or need help in finding vendors, reach out:
External Links
- “CLIP Model and The Importance of Multimodal Embeddings.” Towards Data Science, 11 December 2023. Accessed 9 January 2024.
- “Flamingo: a Visual Language Model for Few-Shot Learning.” arXiv, 29 April 2022. Accessed 9 January 2024.
- “Multimodality and Large Multimodal Models (LMMs).” Chip Huyen, 10 October 2023. Accessed 9 January 2024.





