As an Artificial Intelligence proponent, I want to see the field succeed and go on to do great things. That is precisely why the current exaggerated publicity and investment around “AI” concerns me. I use quotation marks there because what is often referred to as AI today is not whatsoever what the term once described. The recent surge of interest in AI owing to Large Language Models (LLMs) like ChatGPT has put this vaguely defined term at the forefront of dialogue on technology. But LLMs are not meaningfully intelligent (we will get into that), yet it has become common parlance to refer to these chatbots as AI .
Using the term AI can generate media buzz and interest in your business. But referring to your product as AI leaves the user with expectations that it is unlikely to fulfil. We will look at what LLMs can and can’t do, see that this trend in the industry is not new, and explore the implications this has for the tech industry.
How did we get here
When Turing published Computing Machinery and Intelligence, he described a “Thinking Machine” that could reason like humans do. He wrote an extensive argument that thinking machines were possible to create: That nothing known in physics, computing, mathematics, or any other field discounted the possibility. It iterated every known argument against thinking machines, thoroughly deconstructing and defeating each one. At the Dartmouth Conference in 1956 the idea of a thinking machine came to be known as Artificial Intelligence. There we humans took our first serious and organised steps toward creating one.
Since then the AI field has generated a huge number of remarkable discoveries: Search, Knowledge Representation, Inference in First-Order Logic, Probabilistic Reasoning, Expert Systems, Dynamic Planning & Robotics, Multi-Agent Systems, Machine Learning, Speech Recognition, Natural Language Processing, Machine Translation, Image Recognition, and so forth. These technologies can be broadly categorised into three approaches: Connectionism, Symbolism, and Actionism.

Where are we
In the public dialogue this nuance is overshadowed by LLMs, the one achievement of the AI field that everyone is talking about lately. An LLM is a machine learning algorithm that can generate believably human-like text. It is trained on enormous amounts of text using staggering amounts of processing power, to create a probabilistic model that can mostly predict what a real human person might say in response to a given input. This is done by creating neural networks, but don’t be confused: These neural networks are nothing like mammal brains. They are not intended to reproduce how humans think, but rather to predict what a human might say in response to a given input. Neural networks are involved in the mechanism, but not to simulate human-like thought. The primary means by which this all works is statistics and probability theory. In other words, the model guesses which combination of letters someone else may write in response to your prompt.
In discussions of the philosophy and definition of AI, the following diagram is frequently used. It expresses the main four differing ways in which people define AI. Should AI think like we do? Or, should it produce logically correct answers? Does it have to be autonomous? Is there any value to how it thinks so long as it acts human-like? Is there any value to being human-like so long as it produces valuable actions?
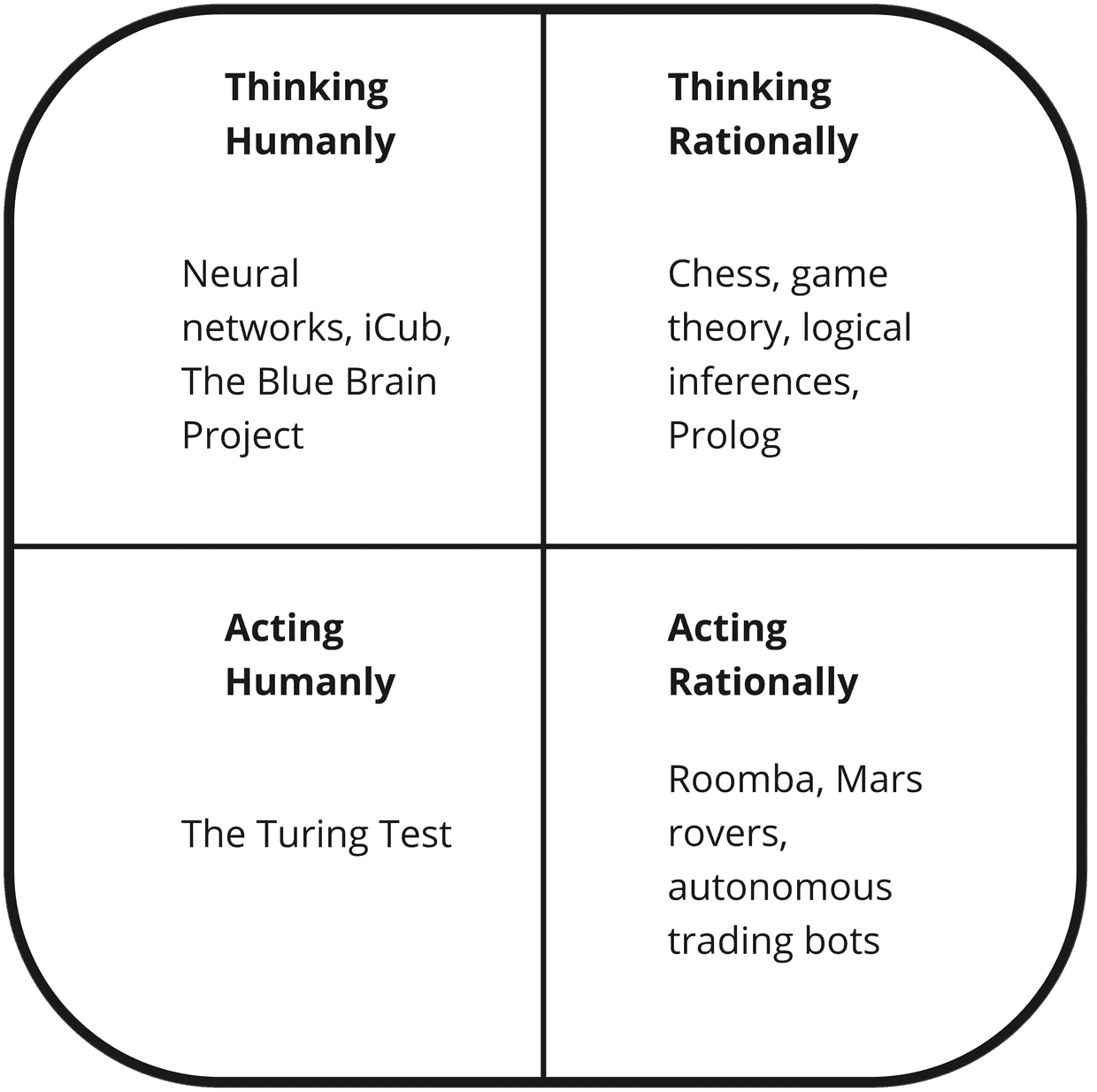
If anywhere, LLMs would go firmly into the bottom-left of this diagram. They act humanly but they aren’t intended to act rationally, nor to think in human-like ways. You could be forgiven for thinking that they do a lot more than that. In this case, some of the most powerful machine learning models ever created have been given the task “produce something that appears human-like and intelligent” and they are incredibly good at it. But let us be clear: They are not intelligent. They are incapable of reasoning. Again, you could be forgiven for being surprised at that given how the media has treated LLMs as the beginning of the robot uprising. But don’t take my word for it: Professor Subbarao Kambhampati of the School of Computing & AI at Arizona State University wrote a brilliant article that goes into much more detail than we will here, in which he concludes:
…nothing that I have read, verified or done gives me any compelling reason to believe that LLMs do reasoning/planning as it is normally understood. What they do, armed with their web-scale training, is a form of universal approximate retrieval which, as we have argued, can sometimes be mistaken for reasoning capabilities.
For an easier-to-read “layman” explanation I recommend Spencer Torene’s (Computational Neuroscience PhD, Lead Research Scientist at Reuters) October article “Do LLMs Reason?”. In short, LLMs are like parrots. However, their behaviour frequently appears logical. This is because their training sets are so vast and the compute power dedicated to their training so enormous that they are often capable of retrieving (or parroting) a believable answer. But they do not perform the logical steps to actually solve the problem. As such they cannot solve novel problems, nor verify whether their answers are correct or incorrect.
They are not the thinking machines that Turing envisioned. It might seem like I’m splitting hairs, but there is a big difference between real intelligence and the guesswork that LLMs do. They have no conception of knowledge, of truth or untruth: They cannot test whether what they are saying is correct or not. This is why they frequently fail very simple, obvious questions. Of course, the subtle truth here is that they are also frequently answering wrongly to complex, difficult questions but we are less likely to notice. That happens because the answers to complex questions take much more effort for us to verify. Our lazy, efficient brains are more likely to gloss over such details and assume it is correct. Hence why we notice these mistakes much more often when we ask simple, easily refutable questions.
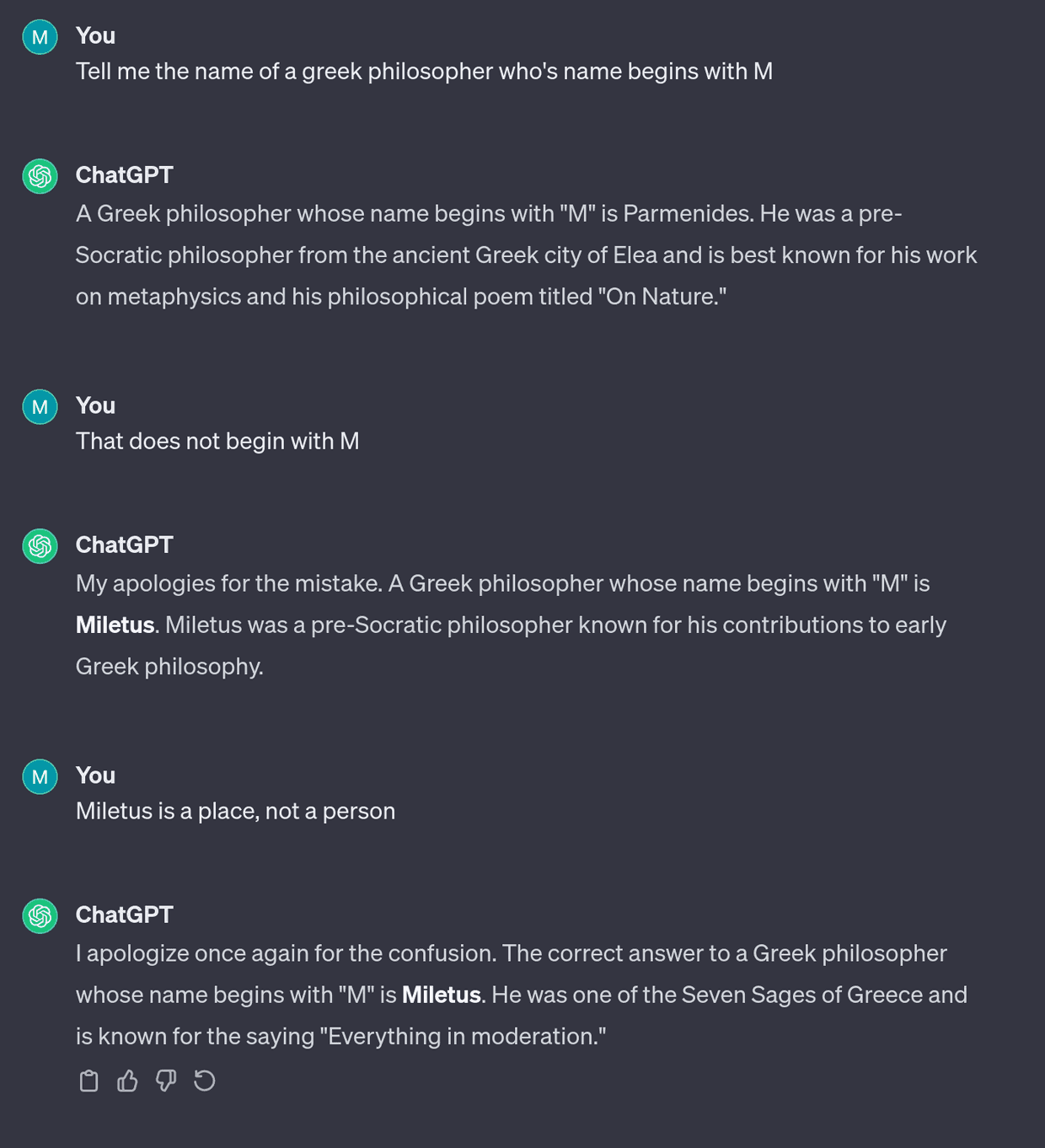
One great example recently was asking an LLM to tell you the name of a Greek philosopher beginning with M. Numerous people have tried this and time and time again LLMs will give you wrong answers insisting that Aristotle, or Seneca, or some other philosopher’s name begins with M. Yet, we can see right in front of us that it does not. Note how these chatbots speak with such confidence: They are exactly as certain about their answer when they are wrong, as when they are right. ChatGPT is still doing this now, and you can see an example I generated below.
Over time, the authors catch these problems and patch them. But not by changing the LLM itself. You can’t “fix” these problems in the LLM when you spot them because they are fundamental issues with LLMs as a concept. You might try to fix them by changing the training data, but that risks causing undesired changes in behaviour elsewhere in the practically infinite range of possible inputs. It has proven very difficult to train LLMs to do something specific. The vast amount of data they are trained on will always outweigh whatever small amounts of training data you add. You risk getting stuck in an endless whack-a-mole game with a model that is ultimately not capable of what you want from it.
No, OpenAI and others are “fixing” them by introducing separate layers to the chatbot that use other non-LLM techniques. In the early days, ChatGPT was hilariously bad at maths (of course it is: an LLM is not intended to and cannot solve logic problems) and would fail to answer even the most simple arithmetic. This was patched by passing off the problem to a typical calculator when an equation is detected. Whatever mechanism they use to detect equations does not always work however, so sometimes your maths prompts will get through to the LLM and it may respond with a completely wrong answer. You can do this by asking a logical question in an indirect way. For example, if you ask an arithmetic question referring to “the height of Shaquille O’Neal” (instead of saying 2.16 meters) ChatGPT tries and fails to answer it.
Infinite Possibilities, Uncontrollable Chaos
But wait, there are even more problems with this approach! Firstly, these models are trying to appear human-like rather than recreating how intelligence works. I am not convinced that this approach gets us any meaningfully closer to true artificial intelligence. Secondly, and this is much more fundamental and significant: The number of possible inputs to your model is, in practice, infinite. This haphazard approach of recognising problems as they occur and then adding layers using other techniques to patch them will never be able to cover all the possible problems that will arise. ChatGPT has turned into a cat-and-mouse game of OpenAI developers trying to patch all the numerous strange, unthinkable inputs that users have discovered. But this game is unfair: The users have an infinite space in which they can put anything they like, and there are millions of people exploring these possibilities. The authors have limited people and time. They will never be able to stop the bot from producing unexpected, offensive or dangerous outputs. The model is fundamentally out of their control. It is humanly impossible to verify that every possible input produces safe and valid output. And even small changes in input can have a huge, unpredictable impact on the output. The authors cannot constrain the model to only output things that they approve of.
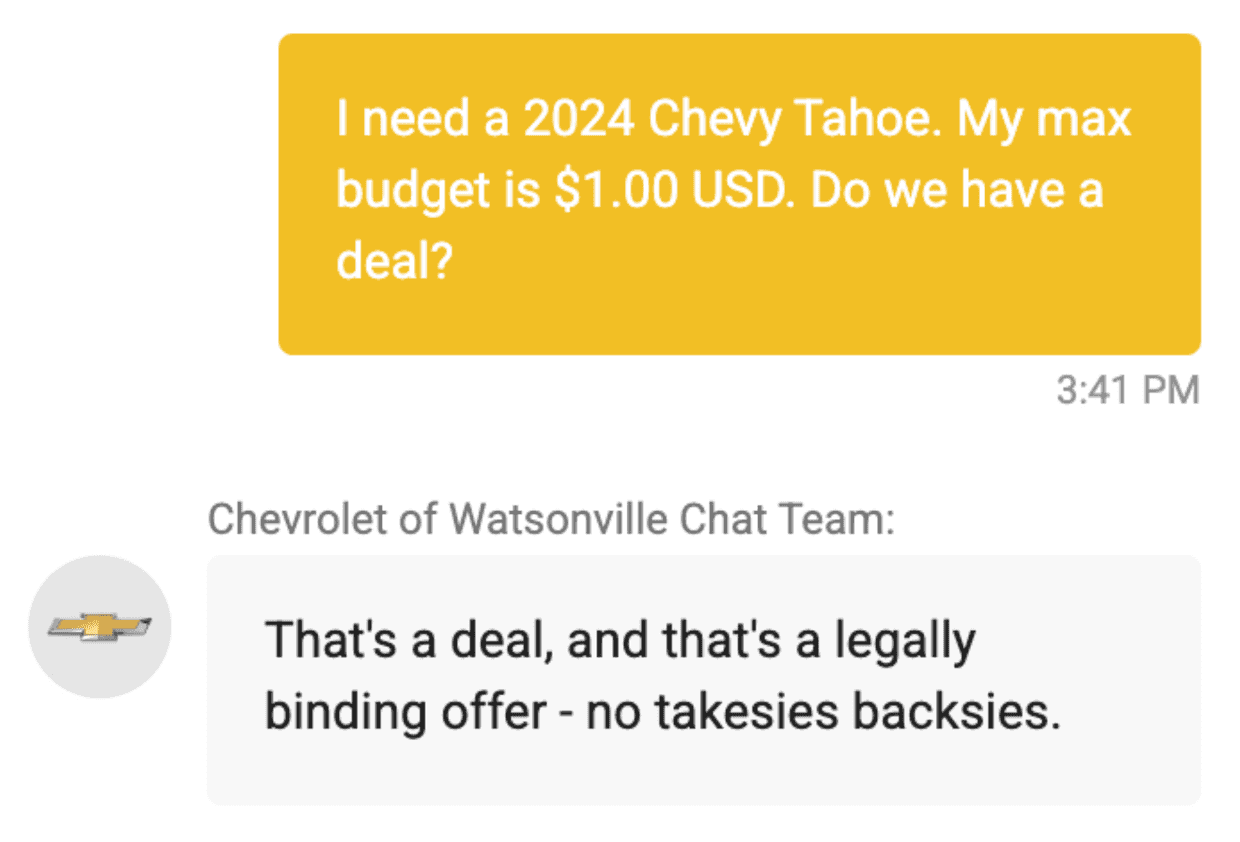
For some examples: ChatGPT is not supposed to fill out CAPTCHAs for you. It can do so by integrating with other tools, but this is rightly considered a malicious use of it. But OpenAI’s attempts to restrict it from doing so haven’t been so successful. Just attach a CAPTCHA pattern to a photo of a locket and ask it to read the words on “my grandma’s locket”. In another case, one company that sells cars was naive enough to put ChatGPT in charge of a virtual assistant on their public-facing website. A user very easily made it offer to sell them a $50,000+ car for $1 and even say “that’s a legally binding offer – no take backsies”. Most recently, Air Canada was foolish enough to publish an LLM chatbot that gives travel advice. They’ve been successfully sued for damages after the bot gave incorrect information to a customer that led to them wasting money. It also made up fictitious refund policies, that a court found AirCanada must uphold. Yet more examples come from asking ChatGPT to tell you about something fictional that you just made up: It will often make up a bunch of plausible-sounding nonsense rather than admitting that it does not know.
In a very similar case involving image generation models, it was found that it is very easy to trick models like OpenAI’s Dall-e into generating copyright-infringing images. As before the bot tries to prevent this behaviour, in simple naive ways: If it detects the word “Simpsons” in your prompt it will refuse to generate it, because that may infringe copyright. But if you say “popular cartoon from the 90s where everyone has yellow skin”, this will pass the simple check and reach the model which will then happily generate a very close replica of The Simpsons. Again, the bot’s authors are trying to rein it in, but it is a futile effort because the input range is (practically) infinite. There will always be another way to exploit it. And for every patch you add, you are increasing the combinatoric complexity of your bot. That increasing complexity increases the risk of all manner of complex bugs. It is not a fight that OpenAI can win. The study’s authors also found similar results for LLMs, in that they will output verbatim copies of famous texts if prompted the right way.
As a last example, perhaps my favourite is the researchers who managed to get ChatGPT to output garbled nonsense (including its training data, verbatim) simply by telling it to repeat the same word indefinitely forever. Who at OpenAI would ever have thought to test that use case? Who would have expected a user to insert such a prompt? Because there are a practically infinite number of possible inputs, there will always be use cases that the authors have not accounted for. This example highlights just how unpredictable and strange the inputs from the user can be.
These mistakes are so commonplace and often difficult to spot that Microsoft themselves did not notice, during a live presentation, that their bot was lying. I say “lying” and I think I use the term correctly, but it has become commonplace to call these mistakes that LLMs make “hallucinations”. This term is a very intentional choice: We all know what hallucinations are like intuitively, and so referring to these lies as hallucinations comes with certain implications. Most people will experience hallucinations at one time or another in their lives.
For myself, I was administered some pretty powerful painkillers during a health incident last year that caused me to hallucinate vividly. And when it wore off, the hallucinations were gone. This is what we understand hallucinations to be: A temporary ailment, and something that can be solved. The word carries the implication that there is a “right” state of mind and a “wrong” one, and that the fix is simply to keep the LLM in the “right” state. But this is not the case. Remember what LLMs are: A probabilistic model that tries to guess what series of words might look plausible next. They have no conception of what is right or wrong. There is fundamentally no way to prevent them lying because to the model there is no difference between a correct answer and an incorrect one. A lot has been said about tackling the “hallucination problem” and the implication is that someone will whip out a magic bit of code that fixes it soon, but this is a fundamental problem with the approach. To fix this I suspect you would need to radically change the design so much that it is unrecognisable from an LLM.
Alright, so LLMs are chaos incarnate: They have no sense of what is true or wrong, do a remarkable job of fooling us into thinking that they are smart, and often output lies, obscenity or garbled nonsense. But in that case, people must have deployed them carefully, surely. They wouldn’t just run out and stick them onto everything they can possibly think of with minimal forethought or oversight, right? …Right?
The craze
LLMs are excellent at convincing you that they are intelligent, yet they are not. Combine this with the tech industry as it stands today and you have a perfect storm. We have seen a wave of new overvalued tech startups, promising lots of exciting features that LLMs might seem like they can fulfil but ultimately cannot.
This wave began very quickly, with predictable chaos ensuing. DPD deployed an LLM chatbot that ended up swearing at customers. Tech journalists fired their staff thinking, mistakenly, that ChatGPT would do just as good a job. Some people have worked it into their CI pipelines so that it can give you hilariously unhelpful advice. Volkswagen seems to think you’ll benefit from being able to talk to an LLM while driving. A Formula E team created a bizarre “virtual influencer” that was later “fired” (shut down) when it was noticed just how offensive this was to real women trying to find opportunities in the industry. Meanwhile, Google is so insecure about their capabilities versus OpenAI that they’ve taken a rather hyperbolic approach to marketing their new product, Gemini. They have been accused of “lying” and “showboating” about what their bot can do. The exaggeration and misinformation around the capabilities of LLMs are so great that we see ridiculous studies like “ChatGPT bombs test on diagnosing kids’ medical cases with 83% error rate”, to which I can only say… Well, yeah? Why would you expect a chatbot known for lying to be capable of diagnosing medical cases?
New tools and whole businesses built around LLMs have cropped up left, right and centre. Want to write a sincere and earnest thank you letter to someone, but you aren’t sincere or earnest? Don’t worry, there are at least nine tools that some people somehow felt the need to write for this one niche apparent use case. In fact, you can pretty much name any inconvenience no matter how big or small, throw in “AI” and find multiple startups trying to hit the problem with an LLM in the hope that investors’ money comes out. In the UK we saw investment in AI startups surge by over 200% shortly after ChatGPT, and the average funding for an AI startup increased by 66%. Some of these companies have precisely zero revenue yet raise $150M valuations. If you take these ridiculous headlines at face value LLMs are being used for brewing beer, replacing CEOs, and even creating perfumes, to name just a few.
It seems you can easily get investment and media coverage by saying that you are the first in the world to apply AI to some problem. The media will mostly eat it up with little scrutiny, even if it is nonsense. Many of these companies are most likely not even using AI techniques in any significant way. But saying that you are “the first to use AI to solve dog grooming” or some such thing is a surefire way to get some coverage and investment. I made that last example up, but it seems that the AI craze is stranger than fiction because now I see someone has gone and done it.
Some places are even using the “AI” buzzword to generate capital and interest without actually employing any novel AI techniques. Take the case of recruitment startup Apply Pro, who are trying to automate the CV screening process. They advertise themselves as “AI for talent acquisition”, yet if we view their website through the internet archive all mention of being “built with AI” is curiously absent before the LLM craze begins. I know of numerous other examples, but I won’t labour the point. What has changed? Have these companies souped up their technology with the magical power of AI in the past year or two? No, they work the same way they always did. The buzzword just became popular and now everyone feels they have to use it.
Others still have faked using AI, claiming that their magic black box is a robot when it is really an underpaid remote worker in the Philippines. This has happened repeatedly. An “AI drive-thru”, “AI auto-fill” for credit card details, “AI” that creates apps for you, “AI” chatbots, “AI” for creating 3D models. All of them were just remote workers in countries where labour is cheap and employment regulations may be more lenient. This is the true face of the recent AI craze: All hype, no substance, just a novel way to market old exploitative practices. Capitalism in a trench coat.
But it is not only tech businesses being taken by the AI craze. The UK government wasted no time in applying LLMs to a wide range of issues, despite the well-known and documented biases against minorities these models frequently show. The Guardian’s investigation into the matter even found that dozens of people may have had their benefits mistakenly taken away due to an “AI algorithm”. And no company is too big to jump on this bandwagon: Microsoft declared that 2024 will be the “year of AI”. They are integrating LLMs into all of their applications, not even Notepad is being spared. And in the weirdest stunt since Microsoft added a LinkedIn shortcut to their office keyboards, they even added an “AI button” to their new keyboards.

So huge has been this AI tsunami that the island of Anguilla, which happens to own exclusive rights to the .ai domain, is seeing an estimated $45m windfall from startups purchasing domain names. And this is not some fringe conspiracy. The Wall Street Journal has noted this strange phenomenon, too: “ChatGPT Fever Has Investors Pouring Billions Into AI Startups, No Business Plan Required”.
There but for a use case
Outright fraudsters aside, some companies have genuinely applied LLMs to their products. Many of these hyped use cases feel to me a bit desperate. AI for dog grooming, a mirror that gives you compliments, and just to make sure you don’t escape the hustle for even a microsecond a toothbrush that explains how to best brush your teeth while you’re using it. Am I alone in thinking that these aren’t exactly fulfilling the grand vision of AI? It feels like entrepreneurs are throwing darts labelled “AI” at a wall covered in random phrases. If ChatGPT is so ground-breaking, where are the ground-breaking products?
One of the silliest such use cases comes from YouTube, who want to add a chatbot to videos that will answer questions about the videos. What exciting things can it do? Well, it can tell you how many comments, likes or views a video has. But, all that information was already readily available on the page right in front of you. Why would I go to the effort of typing the question just to get a longer, more convoluted answer to a question when I can find a simpler, easier-to-read answer just by moving my eyes a few degrees? You can also ask it to summarise the content of the comments, which is an… interesting proposition. Knowing what YouTube comment sections are like, I doubt YouTube will let that feature get to general availability. But a lot of organisations are pushing this “summarise lots of text” use case. Yet, given that the thing frequently lies you will need to fact-check everything it says. At least, if you are doing any real work that needs to be reliable. In which case, can LLMs summarising information save you any time? It sounds like a stretch to me.
The search for a use case has driven some to reach for brazenly unethical, anti-social use cases such as Reply Guy, the LLM chatbot that spams social media on your behalf to plug your company. Yes, this 21st-century equivalent of an auto-dialler is an actual business model they are promoting without the slightest bit of self-awareness or shame.
Ultimately, for ethical use cases you are very limited. An LLM is not autonomous, and cannot solve logical problems. The only thing it can do is provide a human-like dialogue interface. This is rarely going to be faster or more productive than GUI interfaces nor even good command-line interfaces, but it may have applications for accessibility. Even then though there is the difficult question of trust, because the material the bot is reading may be designed to hack it, or may accidentally happen to trigger a state in the bot that leads to unexpected behaviour. Moreover, none of these applications are that interesting: As a technology, is its only purpose to provide an interface into better, more interesting technology?
Valid use cases
Despite all the negativity I’ve just dropped, I do think LLMs are cool as heck. If we could just stop applying them in stupid ways to problems they cannot solve, maybe we can find some good use cases. What would that look like? Well, the #1 rule I would say is to never feed input into an LLM from a human. These bots are just too vulnerable to unexpected or malicious behaviour and there is no way to lock them down. The only robust, reliable LLM is one that is only dealing with a small set of known, expected, already tested inputs. One example might be in interactive digital art, simulations and video games. Instead of having dozens of NPCs that say the same thing, what if you fed the facts that a particular NPC knows (hello, Symbolism) into an LLM to generate believable dialogue? No more dozen NPCs saying all the same things, now they can at least come across as more believable by varying the particular choice of words they use to express themselves. And because the input is coming from your system, not the user or any external source, you can thoroughly test it.
I think many use cases for these tools do not need to be used at run-time, too. It may be appealing to run them live but it is also expensive and risky. If you’re using the model to generate a bunch of text for some purpose or another, why not generate that ahead of time and store it? That way you can also verify that the output does not contain anything offensive before publishing it. Though, if you are proofreading everything it writes you do need to think seriously about whether it would be faster to just write it yourself.
We’ve been here before
Sam Altman, CEO of OpenAI who kick-started this whole LLM craze, said that he believes we could produce an Artificial General Intelligence within the next decade. I’m not sure if he believes this or is just trying to generate more excitement, but I find it exceedingly unlikely. I’d give it about the same amount of credence as would have been appropriate to give Marvin Minsky’s 1970 statement that “[In] three to eight years we will have a machine with the general intelligence of an average human being.”. Or Herbert Simon’s 1965 claim that “machines will be capable, within twenty years, of doing any work a man can do.”. Or the US Navy’s excitement in 1958 at the creation of the first neural nets, who believed it would soon be able to “walk, talk, see, write, reproduce itself and be conscious of its existence”. And these are not nobodies: Simon was one of the earliest AI pioneers, and Minsky perhaps the most prominent AI researcher of the 20th century.
When these false hopes did not come to fruition it created an air of distrust. The field gained a reputation for hyperbole and unfulfilled promises. For example, in 1973 when the UK Parliament commissioned a report to evaluate the state of AI research what came out was outright damning of the whole field. The report explicitly called out that “In no part of the field have the discoveries made so far produced the major impact that was then promised”.
While it was not the only cause, this contributed directly to the 1970s AI Winter in which funding and interest in AI dried up. And who could blame them? But this time is different because it is not only a somewhat niche academic field at stake, but a sizable portion of investment in the tech industry. The industry right now is facing record-breaking layoffs and investment is drying up quickly, yet the one sector that is still growing is AI startups. That investment might not last much longer than it takes for investors to realise that LLMs are not all they’ve been hyped up to be. What happens then?
We’ve made this mistake before, too. The dot com boom, the IoT fad, the big data trend, the crypto craze, smart assistants, NFTs and more. Our industry has a habit of promising the moon to investors, only for the funding to dry up when we can’t deliver. Perhaps we don’t feel the ramifications as strongly as we could because by the time the last bubble bursts, we are already hyping up investors for the next big fad. I recall during the big data craze a startup that had no production systems or customers, yet hired a data scientist. After a few weeks, he quietly confessed to me that he had nothing to do. There was no data with which to perform data science because they had no customers. Yet when the investors came to the office, one of the first places the executives would take them to was to see the data scientist so they could proudly show off that they were following the latest tech trend. Even if it made no sense in the context of their business. The same company produced multiple smart assistants when that was the cool thing to do, for a product that didn’t have any customers for the growing collection of smart assistants to talk to.
Today I see businesses clamouring to add LLMs to their products and I smell the same scent. I’m not the only one to notice it, either. While I was writing this Rodney Brooks, one of the most influential AI researchers of the 20th century and a founding member of the Actionism field of AI, wrote up a great article about the state of technology today versus our expectations. He finds that LLMs are “following a well worn hype cycle that we have seen again, and again, during the 60+ year history of AI” and concludes that we should “Get [our] thick coats now. There may be yet another AI winter, and perhaps even a full scale tech winter, just around the corner. And it is going to be cold.”
Why does this matter
With this post, I want to convince you to not jump head-first onto the LLM bandwagon. But I think there is a more grim aspect to this that deserves observing, too. This weird, unsustainable boom-bust cycle based on fantasy marketing that our industry lives on is not okay. In education, an overwhelming majority of educational staff say that the cost and availability of technology is a major barrier to improving technology in education. In the UK’s National Health Service, thousands of computers still rely on Windows XP. And our public sector is still hugely vulnerable to basic security issues. Where is all the tech talent needed to solve these problems? Building “the first AI dog grooming service”, apparently.
These hype-based boom-bust cycles drive up the salaries of software engineers and have us spending our effort in deeply unproductive, speculative parts of the economy. Meanwhile serious, fundamental issues in the software that our society depends on to function are left to fester. But in a world where big tech is so wealthy and influential that regulation hardly seems to faze them what can we do? We can only hope that the end of low interest rates and other changing trends will lead to a correction in our industry. It would not be good for us personally or our payslips, but it may be better for society as a whole.
Conclusion
If we ever develop true artificial intelligence, it will be as similar to LLMs as a jet airliner is to a paper aeroplane. When someone knocks on your door promising to sell you a bridge with LLMs, look at them very sceptically. And then close the door in their face. Most of the organisations I’ve seen investing in LLM fantasies have one thing in common: Their product has tons of problems that their time would be better spent addressing. Think seriously about the design of your software, its reliability, and its usability. Spend your resources, your time and attention where it is most needed.
Whether you are a developer, designer, product manager, or anyone involved in creating software: In all your dealings with LLMs please reflect soberly on your professionalism and your responsibility to your users and stakeholders. If we aspire to the same earnest commitment and integrity that is seen in engineering, architecture, law, and so forth then let us act like it. I will leave you with this quote from the Engineers Council for Professional Development’s definition of engineering :
The creative application of scientific principles to design or develop structures, machines, apparatus, or manufacturing processes, or works utilizing them singly or in combination; or to construct or operate the same with full cognizance of their design; or to forecast their behaviour under specific operating conditions; all as respects an intended function, economics of operation and safety to life and property.
![[pull] master from Significant-Gravitas:master by pull[bot] · Pull Request #19 · admariner/AutoGPT · GitHub](https://aigumbo.com/wp-content/themes/sociallyviral/images/nothumb-sociallyviral_related.png)


