
Training Compute of Milestone Machine Learning Systems Over Time
- We compile the largest known dataset of milestone Machine Learning models to date.
- Training compute grew by 0.2 OOM/year up until the Deep Learning revolution around 2010, after which growth rates increased to 0.6 OOM/year.
- We also find a new trend of “large-scale” models that emerged in 2016, trained with 2-3 OOMs more compute than other systems in the same period.
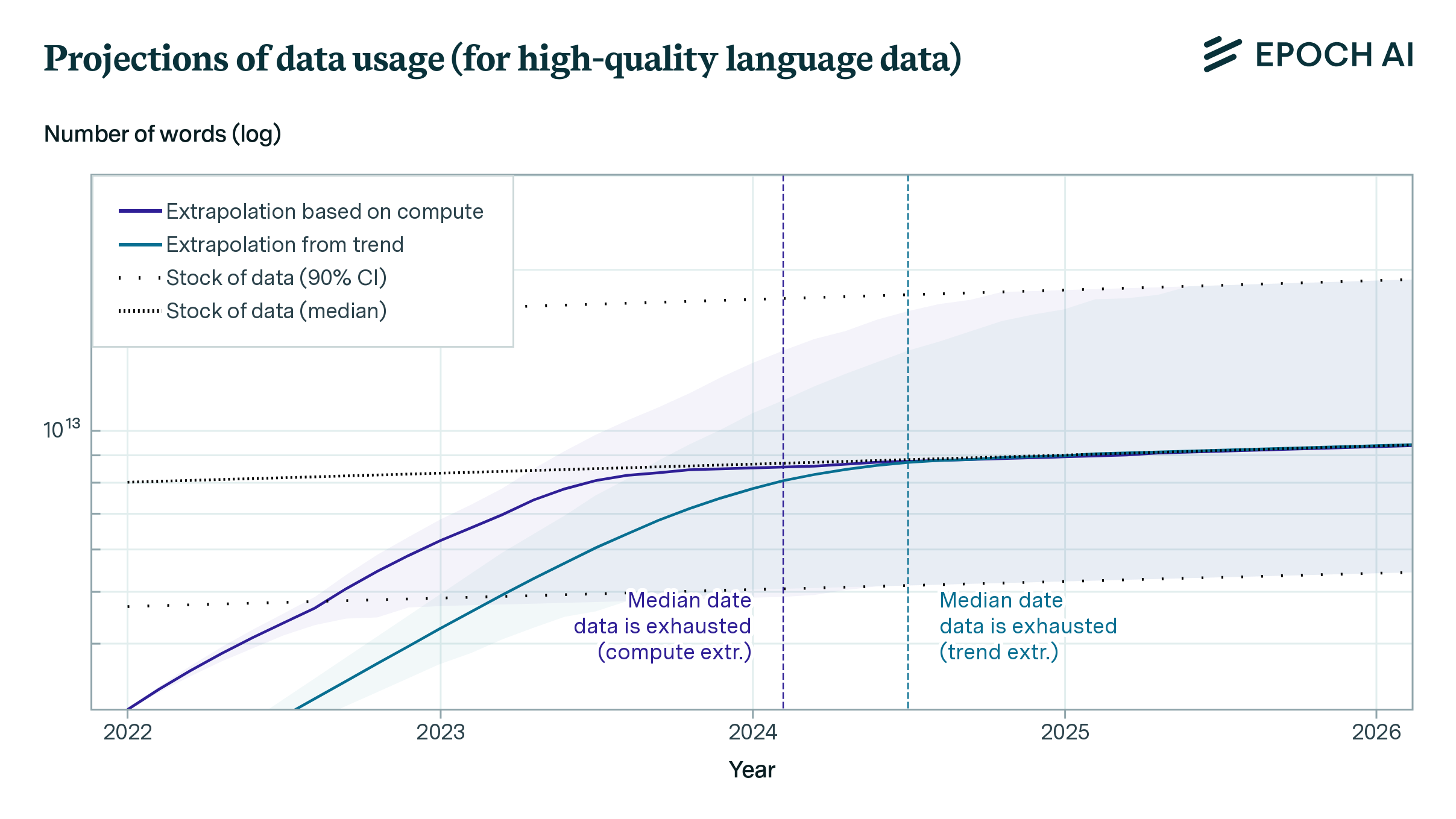
Will We Run Out of ML Data? Evidence From Projecting Dataset Size Trends
- The available stock of text and image data grew by 0.14 OOM/year between 1990 and 2018, but has since slowed to 0.03 OOM/year.
- At current rates of data production, our projections suggest that training runs will use most human-generated, publicly available high-quality text, low-quality text, and images by 2024, 2040 and 2046 respectively.

Machine Learning Model Sizes and the Parameter Gap
- Between the 1950s and 2018, model sizes grew at a rate of 0.1 OOM/year, but this rate accelerated dramatically after 2018.
- This is partly due to a statistically significant absence of milestone models with between 20 billion and 70 billion parameters, which we call the “parameter gap.”

Trends in Machine Learning Hardware
- The use of alternative number formats account, roughly, for a ~10x performance improvement over FP32 computational performance
- Computational performance [FLOP/s] is doubling every 2.3 years for both ML and general GPUs; computational price-performance [FLOP/$] is doubling every 2.1 years for ML GPUs and 2.5 years for general GPUs; and energy efficiency [FLOP/s per Watt] is doubling every 3.0 years for ML GPUs and 2.7 years for general GPUs.
- Memory capacity and memory bandwidth are doubling every ~4 years. The slower rate of improvement indicates a bottleneck in memory and bandwidth for scaling GPU clusters.

Revisiting Algorithmic Progress
- Algorithmic progress explains roughly 45% of performance improvements in image classification, and most of this occurs through improving compute-efficiency.
- The amount of compute needed to achieve state-of-the-art performance in image classification on ImageNet declined at a rate of 0.4 OOM/year in the period between 2012 and 2022, faster than prior estimates suggested.

Trends in the Dollar Training Cost of Machine Learning Systems
- The dollar cost for the final training run of milestone ML systems increased at a rate of 0.5 OOM/year between 2009 and 2022.
- Since September 2015, the cost for “large-scale” systems (systems that used a relatively large amount of compute) has grown more slowly, at a rate of 0.2 OOM/year.
Acknowledgements
We thank Tom Davidson, Lukas Finnveden, Charlie Giattino, Zach-Stein Perlman, Misha Yagudin, Robi Rahman, Jai Vipra, Patrick Levermore, Carl Shulman, Ben Bucknall and Daniel Kokotajlo for their feedback.
Several people have contributed to the design and maintenance of this dashboard, including Jaime Sevilla, Pablo Villalobos, Anson Ho, Tamay Besiroglu, Ege Erdil, Ben Cottier, Matthew Barnett, David Owen, Robi Rahman, Lennart Heim, Marius Hobbhahn, David Atkinson, Keith Wynroe, Christopher Phenicie, Alex Haase and Edu Roldan.
Citation
Cite this work as
Epoch (2023), "Key trends and figures in Machine Learning". Published online at epochai.org. Retrieved from: 'https://epochai.org/trends' [online resource]BibTeX citation
@misc{epoch2023aitrends,
title = "Key trends and figures in Machine Learning",
author = {Epoch},
year = 2023,
url = {https://epochai.org/trends},
note = "Accessed: "
}

 has hit a wall. | by Fabio Matricardi | Jun, 2024")

